I have created my first C&C Generals Zero Hour Mod!
Please don’t hate me for this, I know there are some CNC ZH purists out there that are not going to like this … but there are definitely a lot of people that will appreciate it.
The “Problem”
I see people asking all the time on the CNC ZH forums over the last decade, if superweapons and general abilities can be disabled , and generally, they get the usual unhelpful answer NO NO THIS CANNEE BE DONE. Perhaps folks who want this feature are asking because they want to play casually and or just want to alter the experience of the game to build up a nice turtle base, or perhaps they just wanna play mano a mano, without the general abilities. To me this seems like a reasonable desire.
The Mod
This mod gives the game a more Red Alert feel, and, it’s pretty nice. The game is actually in some respects harder, because people can’t trample eachothers bases with superweapons or special general abilities like MOAB.
And trust me, when I play against 7 Hard AI’s it’s a pretty painful lashing, when they are teamed up against you, lets face it, you are probably going to lose your base in the first 20 minutes!
They said it couldnt be done
Well, they said it couldn’t be done for years but I had a little dig around the variables the game uses in FinalBig and exported the science and specialpower init configuration files, and I could see that this was achievable via two ways:
1. Increase the time for a superweapon reload to exceed 4 hours (i.e. the charge time for all superweapons is greater than an entire match). 2. Increase the number of points required to upgrade, effectively graying out all special abilities, for all players, permanently.
Sure, there might be a few things I missed, potentially, but as far as I can see, people who want to play turtle, and, effectively completely change the way this game works to play base builders, well now they can.
No thanks necessary, just sent me a comment if you enjoy the game mod.
Installing the MOD
You can Download the mod here, simply place the two ini files in C:\Program Files (x86)\Steam\steamapps\common\Command & Conquer Generals – Zero Hour\Data\INI and you are good to go.
So, this isn’t my usual kind of article on haxed. In fact I haven’t been writing on here so frequently. I figured that I could better use my time than simply recording everything I do. More time for learning, discourse, and meditation. However, when it comes to one of my all time favourite games C&C Command and Conquer Generals Zero Hour, I think I am going to make a big exception. Many people will remember trying to install this game on windows 7, and windows xp. It’s not that much fun – mainly because the engine has huge graphics problems, and, the game is zoomed in so much it is almost unbearable. Here is a guide that will help you get the best out of C&C Generals.
This guide will show you how to get these kind of results, 1920×1080 (And up to 4k if you desire). Which you will note are pretty spectacular mainly due to the efforts of the authors of gentool and the probar mod.
1920×1080 to 4K Resolution, Maximum Zoom in and Zoom Out, unlock 30 fps to 100fps+, performance tweaks and more.
Looking pretty tight tight tight general.
What you will need is gentool. The official site can be found here. Apparently the gentool doesn’t work with the latest steam release, and was designed for origin. However if you obtain genpatcher, another community tool designed to make installing gentool and probar easier, it will be able to replace the direct8 dll necessary to unlock high resolution, extended cameraheight, and unlimited FPS. I play on 75fps to 100 fps, however you may note; and this is quite frustrating – in single player skirmish mode the engine is locked to 30FPS.
There is actually a really simple solution to this, use network mode. It seems that the way the games simulation is designed for single player has a static fps ticks clock, it means that if we doubled FPS we only double game speed. For network play, there is some additional complication with the synchronisation of players, and therefore it is possible to unlock the game to much, much higher FPS, 100FPS and beyond.
Unfortunately gentool patcher itself made it so that you only get +100 camera height in network and online play. However I found a way so that players can play both network and possibly online play too, a modified EXE released by the creator of gentool, tucked away on the forums. The reason why the cameraheight is limited in network and online play is the creator of gentool was concerned about cheating, i.e. one player having a significant advantage over the other. The solution to this was to create an exe that was altered, this would mean that if someone is using it, the others players in the network match or online match would also need the exe. So no cheating, because nobody can have an advantage or play without having the same camera height. The modified exe makes it so that the file C:\Program Files (x86)\Steam\steamapps\common\Command & Conquer Generals – Zero Hour\Data\INI\Gamedata.ini is honoured.
Here is a copy of my modified GameData.ini, you can place it in the above directory to increase cameraheight in skirmish, online and network play. Just remember, you also need gentools modified exe, for the overrides to be honored by gentool.
something like the following values are good:
Fixing Zoom (Edit values in C:\Program Files (x86)\Steam\steamapps\common\Command & Conquer Generals – Zero Hour\Data\INI\Gamedata.ini GameData.ini)
For your ease, I attach my GameData.ini. Also note, for some people the path may be different to place the file; also check C:\Users\adam\Documents\Command and Conquer Generals Zero Hour Data if you don’t get the expected results.
It’s probably better you configure it yourself by editing the file and changing the above referenced lines. Now, that’s the zoom fixed. You will also need to install the gamebarpro and the modified exe. For ease I include all of the necessary files in this zip. But you can find them all on the gentool and genpatcher official forums!
All Necessary Patches (for steam/origin release of C&C Generals Zero Hour)
The above link I compiled all of the different patches I’m using to achieve the results you can see. You can just google the filenames in the archive though, as its understandable you probaly want to download directly from the author/official community sites!
A breakdown of All C&C Patches Zip File 1. CnC_Gen_Gamedata.zip – misc probably not needed tbh 2. ControlBarProZH_V1.2_1920x1080.zip (available from gentool site, or by using genpatcher). Genpatcher will install controlbarpro and gentool. 3. GenPatcher 2.08.zip (auto installer for most recent version of gen patcher+Controlbar). 4. GeneralsZH104MODEXE.zip (Modified EXE for Zoom on Network/LAN/Online Games) note this will only work with the other players if you all use same exe. 5. GenTool_v8.9.zip (latest release of gentool)
I also included 6. finalbig04.zip and finalbig040b.zip, these are the BIG editor for C&C. Not needed. You can ignore it but if you want to edit/mod the game yourself these are necessary.
I’ve been spending less time modding sins of a solar empire II, I actually have about 15 mods I have authored for that game with several thousand subscribers, which surprised me. Nowadays I’ll be spending a bit more time with CNC and Retro games. But I haven’t given up my sins 2 modding yet either!
So all in all, here is a pretty good summary of everything you need.
OPTION A. Genpatcher 2.08.zip (installs gentool latest v8.9) and also installs controlbarprozH. It should give you option what resolution you want i.e. 1920×1080 or 4K.
OPTION B Alternatively you can install gentool and controlbarprozh seperately, however, I could not get gentool/controlbarpro to recognise my installation as legit. It’s because the steam installer for zero hour is newer than the latest release of gentool it seems.
Install Gentool.v8.9.zip (drop dll in main game path) C:\Program Files (x86)\Steam\steamapps\common\Command & Conquer Generals – Zero Hour, and install the controlbarprozh seperately, also installed to C:\Program Files (x86)\Steam\steamapps\common\Command & Conquer Generals – Zero Hour.
After you have done either A or B, you will also probably want to use the effects/animation lag fix. Someone actually released a big file to patch it, which I did not use but its included in the ultimate zip pack above named 0PatrioLagFix.big. The method I use to fix is by editing the options.ini file in C:\Users\adam\Documents\Command and Conquer Generals Zero Hour Data
Change options.ini as follows to fix patriot missile lag, which is pretty severe because of the FX animations/particle effects and the general weakness of the zero hour engine.
Fixing Severe FX Lag (add to bottom of C:\Users\adam\Documents\Command and Conquer Generals Zero Hour Data\Options.Ini)
DynamicLOD = no
ExtraAnimations = no
HeatEffects = no
MaxParticleCount = 100
Come to think of it, I think that’s probably why the game in default vanilla zoomed in so much, so that not too much is rendered on screen, but, with all these changes, you can very happily run 1080p or 4k no problems, and im telling you it plays like a completely new game, especially with the controlbar. The old images are all blurry and just generally unpleasant.
I remember as a kid multiple times attempting to fix zoom, resolution, and the other myriad issues for this game and was generally unable to completely get it working nice as I remember playing it older machines. Frankly though Zero Hour was just a temperamental game even in the year 2000. To think this game is almost 25 years old and can play this well is miraculous.
I hope this helps others, enjoy! 😀 I am so happy to get this game working again nicely and hope you will be too! 😀
So, I know its not my usual article but I know folks will find this useful who perhaps are less technical and need to get the full lowdown on how to achieve this.
In the previous chapter we installed brew and the gh tool so that api commands could be made to github directly. Now, in order to use the gh api binary tool you will need to have brew or be able to install the gh binary thru apt, yum or pkg, or equivalent. In my case I’m using centos9 stream on my desktop and I need to use brew since the default repo does not have it.
First I will authenticate and get my token access setup with gh
[github@localhost ~]$ gh auth login
? Where do you use GitHub? GitHub.com
? What is your preferred protocol for Git operations on this host? SSH
? Upload your SSH public key to your GitHub account? Skip
? How would you like to authenticate GitHub CLI? Paste an authentication token
Tip: you can generate a Personal Access Token here https://github.com/settings/tokens
The minimum required scopes are 'repo', 'read:org'.
? Paste your authentication token: ****************************************
- gh config set -h github.com git_protocol ssh
✓ Configured git protocol
! Authentication credentials saved in plain text
✓ Logged in as meepyuser
The gh tool is pretty neat, it allows you to auth via https or ssh to get your key. In my case I already used ssh-keygen to generate my key in ~/.ssh/ and have added it manually, pretty cool though that it will do this for you. Now there is really no excuse not to use the extended gh api features this binary tool provides.
But look at this carefully, we have a problem here; “! Authentication credentials saved in plain text”. This is a serious problem and shouldn’t be ignored, especially on a product environment. If the repo is sensitive it means someone could take control of the repo if they compromise your filesystem. It’s much better to use a credentials store, such as is standard nowadays in most api and opensource software.
Lets install GCM (Git Credential Manager), because it will encrypt the github token we give it rather than storing it in a plaintext file, and even offer 2FA. That way even if the binary is taken over it is most likely the hacker wont be able to do anything with the token without 2FA authentication. This is a really strong way to protect your software repos in your organisation and you probably really shouldn’t be without it under nearly any circumstance; remember security first, functionality second.
Installing Github Credential Manager
So there are a few ways to do this, the two I think are best is either to use your standard repoistory manager (yum), and if that does not provide the package you should try tarball and compile it manually, failing that there is an automation script that github provide that will download all of the dependancies manually.
We are going to show how to do both but I prefer tarball since there is maximum flexibility, control and vision with what is happening ;
Installing GCM Automagically
curl -L https://aka.ms/gcm/linux-install-source.sh | sh
git-credential-manager configure
As above you see the flags -C declaring the local path for the gcm linux binary executable. That’s important, if your not sure use /usr/local/bin or /bin or type echo $PATH to see what path your using already, and use that. Since /usr/local/bin sits outside of the users ~dir ensure you use sudo or the files may not be written.
export GCM_CREDENTIAL_STORE=cache
You will need to add this export line to your .bashrc or .bash_profile so git knows where to store the credentials.
Now we are logged in we can create a brand new public repo on the remote github site;
$ gh repo create php-prime --public --clone
✓ Created repository youruser/somerepo on GitHub
https://github.com/youruser/somerepo
I’m using –clone, so that the github tool will automatically create a local version of the repo already setup on my machine. That’s pretty neat and super convenient if you have a lot of repos to add and don’t want to have to setup each one individually.
Let’s develop our software ‘somerepo’ for ‘youruser’ where somerepo is the repo name on git and youruser is your username path. All repos are in the format of github.com/user/repo for consistency. Github is indeed, very, very easy to use compared with early tools like SVN subversion, some of us like me are going grey and are unfortunately old enough to remember.heheheh
Since the GH tool has already initialise our repo it is just a case of touching our files, writing our code, comitting it and then pushing it to the github remote repo. It’s really simple to do;
[github@localhost php-prime]$ touch mysoftware
[github@localhost php-prime]$ touch find-primes.php
[github@localhost php-prime]$ vim find-primes.php
[github@localhost php-prime]$ git add *
[github@localhost php-prime]$ git commit -m 'just adding some stuff testing gh api'
[master (root-commit) 8a34e61] just adding some stuff testing gh api
2 files changed, 30 insertions(+)
create mode 100644 find-primes.php
create mode 100644 mysoftware
[github@localhost php-prime]$ git push
fatal: The current branch master has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin master
To have this happen automatically for branches without a tracking
upstream, see 'push.autoSetupRemote' in 'git help config'.
[github@localhost php-prime]$ git push --set-upstream origin master
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 32 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (4/4), 533 bytes | 533.00 KiB/s, done.
Total 4 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
To github.com:aziouk/php-prime.git
* [new branch] master -> master
branch 'master' set up to track 'origin/master'.
[github@localhost php-prime]$ touch somechange
[github@localhost php-prime]$ git add somechange
[github@localhost php-prime]$ git commit -m 'added a file called somechange'
[master 17e2f29] added a file called somechange
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 somechange
[github@localhost php-prime]$ git push
Enumerating objects: 3, done.
Counting objects: 100% (3/3), done.
Delta compression using up to 32 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (2/2), 297 bytes | 297.00 KiB/s, done.
Total 2 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
To github.com:aziouk/php-prime.git
8a34e61..17e2f29 master -> master
Because gh has done the heavy lifting, we can setup a repo with a remote in one line now.
So, that summarises how to install the gh api tool, setup authentication, credentials the credit store, and so on. Remember the credit store cache by default expires tokens used after only 900 seconds. In low medum security settings, or development environments or staging users which are already well locked down, it may be sane and safe to permit greater timelimit for the upper cache expiry, this ca be done like so; either by exporting the GCM_CREDENTIAL_CACHE_OPTIONS as a shell variable; which git runs with or thru the git configuration manually. I recommend the latter. Naturally change 300 to whatever value you would desire. Importantly remembering that if the data is sensitive one has to be careful how long the token expiry is. Certainly for a busy development environment, that has repos with strict permissions already, the security is secured at the user permission level, so the length of the token expiry is irrelevant. This is good, because it means your developers don’t want to murder the administrator of the github devops account. Remember some developers commit a lot, and it is not good practice to use a github user with great scope of permissions, much better to reduce the permissions, and assume that the token indefinitely lasts, that way if it is ever compromised its never a big deal.
The .bashrc file is used to execute commands on user login, and is triggered by the su switch or sshd/pamd. you can check your linuxbrew binary path has been added afterwards by typing ‘brew’.
Of course you can add the PATH the old fashioned way in .bash_profile instead if you don’t want to use eval to alias the brew binary; remember adding the whole path means any binaries can be executed there so be mindful of whether you need really need a path export.
It’s pretty simple, in my case I’m installing brew so I can access the github api, which allows a lot more flexibility of the commands I can run compared to the traditional github binary most people use.
Lets install the ‘github gh’ tool for github api like so;
brew install gh
For a successful installation of brew and its toolsets you may also require the development tools group package available on centos9 stream;
sudo yum groupinstall 'Development Tools'
Pretty simples. But handy if your are using an operating system like centos 9 stream which simply doesn’t have a safe official repo like redhat or debian operating systems.
I have been doing a lot of lab work lately and it has occurred to me that it would be pretty cool to run a 2 vcpu vm with 2gb ram, minimal resources in the lab, to host our own x86 repository for my favourite OS of choice, centos. It’s really easy to do too thanks to yum-utils.
Using my current lab template above, I simply alter a few things like name, vcpus, and increase the initial disk space to 500GB. Which should be ample for now.
Configuring a cronjob to automatically resync the repo daily
vi /etc/cron.daily/update-repo
# create new
#!/bin/bash
VER='9'
ARCH='x86_64'
REPOS=(baseos appstream extras-common)
for REPO in ${REPOS[@]}
do
reposync -p /var/www/repos/centos-stream/${VER}/${ARCH}/os/ --repo=${REPO} --download-metadata --newest-only
done
sudo restorecon -r /var/www/repos/
# exit vim :wq and chmod the cronfile for good measure
chmod 755 /etc/cron.daily/update-repo
Then we install the httpd server and configure it for this path
vi /etc/httpd/conf.d/repos.conf
# create new
Alias /repos /var/www/repos
<directory /var/www/repos>
Options +Indexes
Require all granted
</directory>
#exit vim and restart the httpd with the new root repo
systemctl restart httpd
All done. Now we can configure the local server with our golden image cloud image we’re using to boot from libvirt with our own local repo. Ideally we’d also have a local dns server so we can run mirror.some.tld or similar. In this case the ip address will for now suffice, with a hostname in /etc/hosts of the golden image like local-mirror <centos9-local-repo-ip>, instead so it looks pretty and recognisable in the repo file.
vi /etc/yum.repos.d/centos.repo
# change to local mirror server
[baseos]
name=CentOS Stream $releasever - BaseOS
#metalink=https://mirrors.centos.org/metalink?repo=centos-baseos-$stream&arch=$basearch&protocol=https,http
baseurl=http://local-mirror/repos/centos-stream/$releasever/$basearch/os/baseos/
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial
gpgcheck=1
repo_gpgcheck=0
metadata_expire=6h
countme=1
enabled=1
[appstream]
name=CentOS Stream $releasever - AppStream
#metalink=https://mirrors.centos.org/metalink?repo=centos-appstream-$stream&arch=$basearch&protocol=https,http
baseurl=http://local-mirror/repos/centos-stream/$releasever/$basearch/os/appstream/
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial
gpgcheck=1
repo_gpgcheck=0
metadata_expire=6h
countme=1
enabled=1
# vi /etc/yum.repos.d/centos-addons.repo
# change to local mirror server
[extras-common]
name=CentOS Stream $releasever - Extras packages
#metalink=https://mirrors.centos.org/metalink?repo=centos-extras-sig-extras-common-$stream&arch=$basearch&protocol=https,http
baseurl=http://local-mirror/repos/centos-stream/$releasever/$basearch/os/extras-common/
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-SIG-Extras-SHA512
gpgcheck=1
repo_gpgcheck=0
metadata_expire=6h
countme=1
enabled=1
Finally clean and re-update yum to test config change
dnf clean all
dnf repolist
If you are insisting on running selinux like me, make sure you allow filegetattr;
[adam@centos9-repo-server appstream]$ sudo audit2allow -a -M filegetattr
******************** IMPORTANT ***********************
To make this policy package active, execute:
semodule -i filegetattr.pp
[adam@centos9-repo-server appstream]$ semodule -i filegetattr.pp
libsemanage.semanage_create_store: Could not read from module store, active modules subdirectory at /var/lib/selinux/targeted/active/modules. (Permission denied).
libsemanage.semanage_direct_connect: could not establish direct connection (Permission denied).
semodule: Could not connect to policy handler
[adam@centos9-repo-server appstream]$ sudo semodule -i filegetattr.pp
It wouldn’t go amiss to tag the files either however in this case chcon isn’t necessary because the /var/www context already has the correct mask by default in selinux. 😀
As it turns out you also need read, as well as getattr to actually download the packages (getattr is needed for listing them i.e. ls)
$ sudo audit2allow -a
#============= httpd_t ==============
#!!!! This avc is allowed in the current policy
allow httpd_t var_t:file getattr;
allow httpd_t var_t:file read;
[adam@centos9-repo-server appstream]$ sudo audit2allow -a -M httpdread.pp
[adam@centos9-repo-server appstream]$ sudo semodule -i httpdread.pp
Once again we retry. OK, turns out we do need to set the unconfined files/folder that were written; which can be done like
sudo restorecon -r /var/www/repos/
I guess we’ll add this restorecon -r /var/www/repos/ to our cronjob for good measure to make sure the context is right.
I have previously described how to create a galera cluster using a created libvirt lab. I now describe how to create a master-slave mysql replication lab of the same without utilising Galera and instead using the inbuilt mysql binary-log master and a slave replica synchronising with it’s own user to the master.
Creating the Master and Slave VM’s
As before we create a pair of oneliners, and user-data and meta-data for cloud init to create the two nodes with our provided .ssh/id_rsa.pub key. In this case we only need to recreate the meta-data for the new hostnames and VM instance name. The cloud-init.yaml we created in the previous article is still relevant since that only contains our SSH public key, so we will reuse it.
Above we obtain the ip address of the the two nodes with virsh net-dhcp-leases, and a grep for our name tag used in the creation of the VM’s for easy to view output.
We then login and install the mariadb-server package, since we’re at it lets do it properly and install firewalld too and add a firewall rule for mysql port [3306]. We’ll also install vim, because its awesome fast for editing config files and isn’t present in our minimal base image. We also make sure firewalld and mariadb start on boot.
# Login to Master to install packages
ssh [email protected] -i ~adam/.ssh/id_rsa
yum install firewalld mariadb-server vim
[adam@mysql-master ~]$ sudo systemctl start firewalld
[adam@mysql-master ~]$ sudo systemctl enable firewalld
[adam@mysql-master ~]$ sudo systemctl enable mariadb
[adam@mysql-master ~]$ sudo mysql_secure_installation
[adam@mysql-master ~]$ sudo firewall-cmd --add-service=mysql --permanent
[adam@mysql-master ~]$ sudo systemctl restart firewalld
# Login to Slave and perform the same
[adam@mysql-slave ~]$ sudo yum install firewalld mariadb-server vim
[adam@mysql-slave ~]$ sudo systemctl start firewalld
[adam@mysql-slave ~]$ sudo systemctl enable firewalld
[adam@mysql-slave ~]$ sudo systemctl enable mariadb
[adam@mysql-slave ~]$ sudo mysql_secure_installation
[adam@mysql-slave ~]$ sudo firewall-cmd --add-service=mysql --permanent
[adam@mysql-slave ~]$ sudo systemctl restart firewalld
# For good measure we check firewall-cmd open ports were added as the services we need
[adam@mysql-slave ~]$ sudo firewall-cmd --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: eth0
sources:
services: cockpit dhcpv6-client mysql ssh
-- truncated output
[adam@mysql-master~]$ sudo firewall-cmd --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: eth0
sources:
services: cockpit dhcpv6-client mysql ssh
-- truncated output
We proceed with the masters configuration by giving it id=1 and enabling bin logs for replication.
Make sure you add these in the correct section. Note some distributions still use /etc/my.cnf as opposed to /etc/my.cnf.d/ , such as Ubuntu. It’s clear which one you have since there will be a [mysqld] section. Include the two lines we need to add in there. Once done restart mariadb on the master.
So far so good. Let’s create a user on the master for the slave mysql VM to use for replicating (copying) the data from master node. After creating the new account we flush privileges table for good measure and put the master in a read-only mode to prevent changes for the next step ‘bin file location’ and ‘bin file position’.
[adam@mysql-master ~]$ sudo mysql -u root
MariaDB [(none)]> grant replication slave on *.* to 'replication'@'192.168.122.117' IDENTIFIED BY 'makemereallysecureplease'
MariaDB [(none)]> flush privileges;
MariaDB [(none)]> flush tables with read lock;
A word on Secure Passwords if binding in a publicnet
This is only a test lab so it is safe for us to use a low security password. I recommend you use pwgen or similar to create a secure password in a production environment though, especially if you are binding to 0.0.0.0 and are in an open public net.
If you install pwgen install it, by first installing epel-release repo and then pwgen.
Most people will have a private network backend that sits behind a load balancer or master sql server that is only accessible to the service network. Still it’s better in a non lab environment to always get into the habit of using a secure password; notice in my use case I only give access via explicit static ipv4 of the VM in question to prevent unauthorised access to the db. [this is really much more important in a publicnet setting where there is no option for rich rules with firewalld etc]
Pretty simple, the only important thing is to set the id.
[mysqld]
server-id = 2
Now we’re ready to tell the Slave where the master is. First we need to login to the master sql server to get some important information for the slave we don’t know yet know.
[adam@mysql-master ~]$ sudo mysql -u root
MariaDB [(none)]> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000001 | 328 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.001 sec)
[adam@mysql-slave ~]$ sudo mysql -u root
MariaDB [(none)]> change master to master_host='192.168.122.132', master_user='replication', master_password='test', master_log_file='mysql-bin.000001', master_log_pos=328;
In the legacy mysql master-slave replica’s we need to know 3 things. The credentials for the slave login set on the master (in this case you can see this is set above as the user replication and the password, and also the name and position of the master log file, this is critical for the slave node to know ‘where to sync from’, especially if there is major differences in the two databases. Also, its important to understand later on if you add additional slaves or one of the slaves gets corrupted and needs to be manually resynced with the master.
Checking that the Slave is synching with the replica user using ‘show slave status‘. We use \G for clearer output.
MariaDB [(none)]> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.122.132
Master_User: replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 342
Relay_Log_File: mariadb-relay-bin.000006
Relay_Log_Pos: 641
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Rewrite_DB:
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 342
Relay_Log_Space: 1251
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: No
Gtid_IO_Pos:
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 1
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)
ERROR: No query specified
As we can see the mysql-slave is correctly configured. Once this is done we can instruct the master to continue processing queries as normal, removing the read lock on the tables;
You can see how important it is to properly label servers with cloud-init and virsh, vmware, openstack etc. Since performing maintenance and upgrades of any kind it can be easy to mistake the server otherwise, and can result in some pretty unpleasant confusion for yourself and your clients. We can quickly test that the slave is syncing with the master by creating a new database, too.
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| test |
| testsync |
+--------------------+
6 rows in set (0.001 sec)
Sure enough our replica is taking output correctly from the master and replicating data.
You may, if the dataset on the master is pre-existing and very large, want to backup the mysql database on the master for good measure with mysqldump
In our case it was two new servers so this step wasn’t necessary for the lab demonstration.
Another useful command you might want to use is show processlist; which is handy for debugging issues that may arise;
MariaDB [(none)]> show processlist;
+----+-------------+-----------+------+-----------+-------+--------------------------------------------------------+------------------+----------+
| Id | User | Host | db | Command | Time | State | Info | Progress |
+----+-------------+-----------+------+-----------+-------+--------------------------------------------------------+------------------+----------+
| 8 | system user | | NULL | Slave_IO | 12266 | Waiting for master to send event | NULL | 0.000 |
| 9 | system user | | NULL | Slave_SQL | 274 | Slave has read all relay log; waiting for more updates | NULL | 0.000 |
| 10 | root | localhost | NULL | Query | 0 | starting | show processlist | 0.000 |
+----+-------------+-----------+------+-----------+-------+--------------------------------------------------------+------------------+----------+
3 rows in set (0.000 sec)
I hope that this is useful to someone, as there are not a lot of really good and simple documentation showing this process in a clear to understand way online.
Hey, so it has been a little while since I’ve ventured into libvirt and I have noticed a few things, like support for kimchi on modern versions of python is kind of lacking, so instead of firing up a small wok-kimchi html5 lab I took a different route to what I would normally prefer, to create the lab from the ground up without any helper framework or GUI.
This involved a few things, mainly to install libvirt and kvm-qemu, and then to create a virsh install script utilising cloud init user-data and meta-data for the hostnames and adding the ssh key of my cloud user.
The Box I use is a remote HP Z440 with vtx extensions for virtualisation, these are required and if you are trying to achieve it will need to enable virtualisation support in the BIOS, which oddly in my case could be found in the “Security” Section of the HP Bios.
Once virt is installed we can concentrate on creating a cloud init files, which will be used by virsh-install during VM creation.
I also retrieved the latest cloud image provided by Redhat/CentOS ‘CentOS-Stream-GenericCloud-9-latest.x86_64.qcow2’. For a list of CentOS cloud ready images you can look at https://cloud.centos.org/centos/9-stream/x86_64/images/. Remember the older images (older than CentOS 8/9 are probably not safe to run. Always use an up to date image.
Cloud Init
In order to use these images, unlike back in the day there is no default local user only password to login via KVM. You will need to use the more established way of adding your password or SSH-key via cloud-init automation.
First we will place our qcow2 image in the /var/lib/libvirt/images repoistory. It is important to organise your images as best you can and I recommend against using images in non standard directories, it may upset selinux and permissions and create for confusing lab environment;
mv /home/adam/CentOS-Stream-GenericCloud-9-latest.x86_64.qcow2 /var/lib/libvirt/images
# lets create a cloud init directory
mkdir /var/lib/libvirt/images/cloudinit
vim cloud-init.yaml
The Cloud Init YAML File structure
The cloud init file structure allows you to set a variety of different things, including running scripts, attaching assigning hostnames, pre-installing packages, setting passwords and installing ssh public keys for secure login post-boot cloud-init. Cloud init only runs once so it’s important to understand any script you want to frequently run, should be installed to crontab with cloud init so that it runs independently after first-run. etc. In our case we want to add the adam user to sudo and set a /bin/bash shell with an authorized public key from my test lab.
If you want to create your own key you will need to replace the section – ssh-rsa {} with your own generated rsa key (or equivalent cipher like ecdsa etc etc);
Creating the Meta Data File
There are two files, the above is the ‘user-data’ component of cloud-init, we also want to provide a hostname to our machine so on build time its system hostname is set, and it is clearer for us what machine we are logging into. Maybe for a small setup such things aren’t important but in a cluster, or large environment having context to the commandline of the machine you are working on could be the difference between life and death, you don’t want to restart the primary node in a cluster accidentally instead of one of the ‘slave nodes’. So Labeling is important and it it’s really easy to do;
In my case I will create two more meta-data files for my other 2 Galera nodes ‘galera2-metadata.yaml’ and ‘galera3-metadata.yaml‘ with different node numbers ‘galera-2’ etc. It’s useful if you keep these files in somewhere safe or clear like /var/lib/libvirt/images/cloudinit or similar. You will reference them using the –cloud-init command and the user-data and meta-data suboptions later when creating the Virtual machines.
Generating a Key to Login to Cloud init
# create a (by default) rsa key for your logged in user
ssh-keygen
# output the safe public key to add to cloud init for login later
[root@localhost cloudinit]# cat ~adam/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDB1D9CP4jqWxKw4ug+lR2zol7W6oJZ7wuliMt8aqlYekUBk7Pi7apQakc7rqjYD+b4iUDig0/4Zk4u6DC8WPgVr6o60fV7sdpoj0GBuxL+voGE0YV84zmorHoM8TCfLeMN3AdM0EMcT2NI8V/dmZ7uILYLYaXB+RRLv1QoMiL6zLGhLOfhdVKdvmbNqNcrvAEonnzQCVhFjRied2CfhnuH9tNXzGT5Y8wz0E9I8gQQp6GCyU7HnCHW8CLWpymZIrt2y7/Bi4XlKAbvaUFZJ9XLNsAK3gBC/VygIVQkWp9o3Y+KOmOsmsS51xJsigfDI0UMRdehdNEN+6vm7Eft9QZYHOg1xoTyJkgiFs9yCRFSRuXvFSsFLXUq5TFLv73qquKE6e/STORKobF2V7LaOuvbw1BIt2zo4v4c4toyaB5hshojO7bpORzhH8K43vEs0VW2ou9Zo8L3DwmZv6qFAy88BDCAIHoElgc3fmddlZJfCvcN4ZWDuISEP/j2oVuDT40= [email protected]
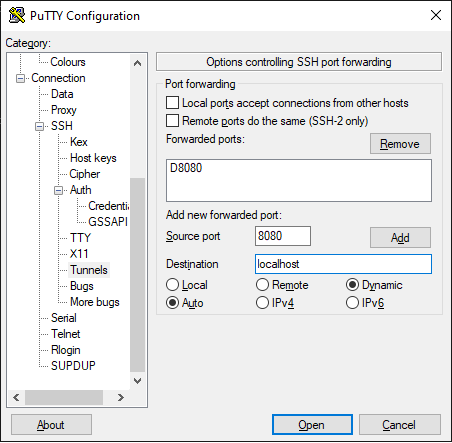
As you can see it is a very simple process to generate the key for your user. In my case the adam user is located on the same remote machine I am running the libvirtd hypervisor. However if the network routes are bridged to the local adapter on the hypervisor I could login from anywhere in the adjoined network. For convenience and security purposes I keep everything exposed locally to the remote hypervisor only, and for vnc sessions I use a dynamic tunnel on my desktop, which is frequently used to safely connect to unecnrypted local vnc sessions on the remote hypervisor. I use a socks5 configuration Dynamic Tunnel to achieve this on linux and windows machine like illustrated below;
We’ll see why this can be important and useful later.
Creating the Virtual Machines
Now we have all the necessary cloud init files created, a ssh user and key for cloud init for us to access the new vm ip addresses via ssh login and the ability to vnc to console via encrypted tunnel. Let’s go ahead and create the 3 Virtual Machines that will form part of the Galera Cluster Lab Environment.
# building out the cluster nodes
./make-galera-cluster.sh
# tearing down the cluster nodes
./destroy-galera-cluster.sh
A little bit about the virsh-install parameters. name is the label of the virtual machine. memory and vcpu’s are self explanatory. the disk size creates a 10gb qcow2 image based on the ‘golden image’ (master image reference) of Centos-Stream-9, and –cloud-Init provides our user-data and meta-data for the cloud init service to set the hostname and add our ssh key respectively. the disable=on parameter disables cloud-init after the first run, which i recommend. At least in my case virsh obtains 2 dhcp leases for the same label hostname which causes for confusion. Unless you really need to run cloud init more than once, leave it that way. –noautoconsole prevents you from being attached to the virtual machine console, and the –network bridge defines the local nic interface to use for the dhcp network lease subnet of the virtual machine. Simple, right?
Configuring the Galera Nodes
We should by now have 3 nodes running each with an IP dhcp lease on the virbr0 bridge interface.
[root@localhost cloudinit]# virsh net-dhcp-leases default
Expiry Time MAC address Protocol IP address Hostname Client ID or DUID
------------------------------------------------------------------------------------------------------------
2024-02-24 02:18:19 52:54:00:1b:49:65 ipv4 192.168.122.219/24 galera-1 01:52:54:00:1b:49:65
2024-02-24 02:19:41 52:54:00:6c:00:83 ipv4 192.168.122.247/24 galera-3 01:52:54:00:6c:00:83
2024-02-24 02:19:40 52:54:00:c6:17:7b ipv4 192.168.122.199/24 galera-2 01:52:54:00:c6:17:7b
In my case cloud-init actually creates 6 leases for the 3 VM’s with one dead ip that was used during cloud init boot. I find this irritating so I wipe the stat file and restart my vm’s so I don’t have to try two ip’s until I get one that is alive;
I resent the way dnsmasq works here, it certainly makes it easier to login to our first node to configure the packages for galera.
From earlier when we setup our Tunnel for VNC on the dynamic socks port 8080:localhost; we may want to access the VNC sessions to our created VM’s in an emergency. Let’s test this works OK.
[root@localhost cloudinit]# virsh list
Id Name State
-------------------------
21 galera1 running
22 galera2 running
23 galera3 running
[root@localhost cloudinit]# virsh vncdisplay galera1
127.0.0.1:0
[root@localhost cloudinit]# virsh vncdisplay galera2
127.0.0.1:1
[root@localhost cloudinit]# virsh vncdisplay galera3
127.0.0.1:2
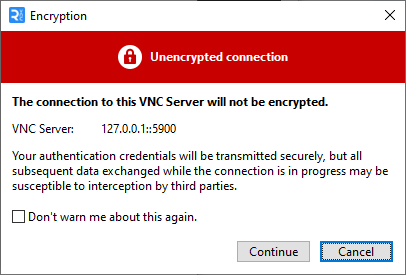
Remember, if you get a message like this you can safely ignore it. Why? Your SSH2 tunnel effectively makes the session transport encrypted locally at both points, so there is no opportunity to intercept the plaintext session by other parties that may sit in the middle, as it’s effectively a private tunnel like vpn between you and the hypervisor (No MIM Can take place that it is warning you about). The reason this is is because the socks5 is a ‘transparent’ proxy, so VNC doesn’t know or look to check socks5 traffic encapsulated by sha based encryption via our dynamic ssh tunnel]
Testing first, Automation Second, To Ansible or Not to Ansible?
Of course the next step after manually testing our cluster will be to consider automating these package installations utilising the user-data cloud-init file which can install many different packages and repo’s to our machines. We can include as meta-data additional configuration files, system package installation variables for our virtual machines, and these processes can be carried out by cloud-init.
For a Home lab setup the best (and probably most commercially flexible) approach is to let virsh and cloud init to handle the building of the VM and the installation of packages perhaps, and ansible can take care of any advanced packages and configuration changes to the cluster, because cloud-init isn’t cluster-aware, but ansible playbooks very much can be written to do that.
I think ansible will be useful later for my lab, as changing the nodes of the cluster to different consistency or performing upgrades isn’t something you could handle thru cloud-init anyways, except for brave and foolish lost souls, perhaps! 😀
In order to create an effective playbook testing manually is necessary first, unless you are fortunate to find an ansible playbook which has already been thoroughly tested by someone else to do the same. In any case you will probably want to get some hands on experience to understand what the playbook automation actually does, otherwise your sorta firing blind into the wind..
Installing Galera on the 3 Nodes Cluster
sudo dnf -y install mariadb-server-galera
I saw some versions of debian actually come with mariadb aliased repo, but CentOS package specifies ‘mariadb-server-galera’. We are using 10.11.6, as you can see below;
[adam@galera-2 ~]$ dnf info mariadb-server-galera
Last metadata expiration check: 0:00:58 ago on Sat 24 Feb 2024 11:19:55 AM EST.
Installed Packages
Name : mariadb-server-galera
Epoch : 3
Version : 10.11.6
Release : 1.module_el9+853+7b957b9b
Architecture : x86_64
Size : 39 k
Source : mariadb-10.11.6-1.module_el9+853+7b957b9b.src.rpm
Repository : @System
From repo : appstream
Summary : The configuration files and scripts for galera replication
URL : http://mariadb.org
License : GPLv2 and LGPLv2
Description : ... [shortened]
About Releases, Stability, Support, Developent Cycles
Generally we don’t live too close to the cutting edge [unless there is a good reason like support to do so]. The advantage of stable CentOS 9 stream packages is the stability and future supportability, most repo’s will have patched issues with earlier releases that are found normally in the first few months after release. According to the vendor 10.11 is the latest stable release, and considering the development cycle is important for Long Time Support (aka LTS).
It actually is important to understand that a General Availability (GA) Release may have much less future support and will not be maintained for security updates or package updates in the stream rep , a veritable nightmare a good technician is worthy of avoiding his client.
Simply using a stable LTS is the best approach since you will get support for 5 years. So in our case we will expect support to end 5 years from the release date which is sometime between 2028-2029. Probably long enough. Which is a big difference two 2025 or 2026, and likely to be a real headache sometimes, as releases can be library and cross-dependency breaking in larger more complex software stack and development environments. Most companies don’t spend so much time on such matters, but it’s really important man, and in my experience working in managed support at Rackspace for 3 years, I saw a lot of businesses who didn’t spend so much time on this matter really wish that they had when their application came tumbling down by a forced upgrade gone wrong that if they used LTS they could have avoided. etc etc. Last of all one other important consideration is whether they want to install the latest stable from the centos 9 stream repoistory, or if they want to use a specific version from the vendor repo. Again, this depends on the clients objectives and is an important consideration when carrying out implementation in a commercial environment.
Configure Galera Node
Before we begin we need to remove the anonymous mysql user and test data and ‘make mysql secure’. This can be done with the simple command below. Not much more to say as this is standard practice since forever;
[adam@galera-1 ~]$ mysql_secure_installation
Let’s configure our first Galera Node on the galera-1 virtual machine. We need to reference the other addresses of our node (wsrep_cluster_address), we need to name the node for legibility (wsrep_node_name, and its not a uuid so be warned), and we need to consider what wsrep_sst_method we are using. Finally we’ll need to set the ws_rep_on=1 before stopping our service and insuring that /var/lib/mysql is empty and does not have any other data in it that is either important or will prevent the cluster creating the db structure for the cluster.
# This file contains wsrep-related mysqld options. It should be included
# in the main MySQL configuration file.
#
# Options that need to be customized:
# - wsrep_provider
# - wsrep_cluster_address
# - wsrep_sst_auth
# The rest of defaults should work out of the box.
##
## mysqld options _MANDATORY_ for correct opration of the cluster
##
[mysqld]
# (This must be substituted by wsrep_format)
binlog_format=ROW
# Currently only InnoDB storage engine is supported
default-storage-engine=innodb
# to avoid issues with 'bulk mode inserts' using autoinc
innodb_autoinc_lock_mode=2
# Override bind-address
# In some systems bind-address defaults to 127.0.0.1, and with mysqldump SST
# it will have (most likely) disastrous consequences on donor node
bind-address=0.0.0.0
##
## WSREP options
##
# Enable wsrep
wsrep_on=1
# Full path to wsrep provider library or 'none'
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
# Provider specific configuration options
#wsrep_provider_options=
# Logical cluster name. Should be the same for all nodes.
wsrep_cluster_name="galeracluster"
# Group communication system handle
wsrep_cluster_address="gcomm://192.168.122.219,192.168.122.247,192.168.199"
# Human-readable node name (non-unique). Hostname by default.
wsrep_node_name=galera-1
# Base replication <address|hostname>[:port] of the node.
# The values supplied will be used as defaults for state transfer receiving,
# listening ports and so on. Default: address of the first network interface.
#wsrep_node_address=
# Address for incoming client connections. Autodetect by default.
#wsrep_node_incoming_address=
# How many threads will process writesets from other nodes
wsrep_slave_threads=1
# DBUG options for wsrep provider
#wsrep_dbug_option
# Generate fake primary keys for non-PK tables (required for multi-master
# and parallel applying operation)
wsrep_certify_nonPK=1
# Maximum number of rows in write set
wsrep_max_ws_rows=0
# Maximum size of write set
wsrep_max_ws_size=2147483647
# to enable debug level logging, set this to 1
wsrep_debug=0
# convert locking sessions into transactions
wsrep_convert_LOCK_to_trx=0
# how many times to retry deadlocked autocommits
wsrep_retry_autocommit=1
# change auto_increment_increment and auto_increment_offset automatically
wsrep_auto_increment_control=1
# retry autoinc insert, which failed for duplicate key error
wsrep_drupal_282555_workaround=0
# enable "strictly synchronous" semantics for read operations
wsrep_causal_reads=0
# Command to call when node status or cluster membership changes.
# Will be passed all or some of the following options:
# --status - new status of this node
# --uuid - UUID of the cluster
# --primary - whether the component is primary or not ("yes"/"no")
# --members - comma-separated list of members
# --index - index of this node in the list
wsrep_notify_cmd=
##
## WSREP State Transfer options
##
# State Snapshot Transfer method
wsrep_sst_method=rsync
# Address which donor should send State Snapshot to.
# Should be the address of THIS node. DON'T SET IT TO DONOR ADDRESS!!!
# (SST method dependent. Defaults to the first IP of the first interface)
#wsrep_sst_receive_address=
# SST authentication string. This will be used to send SST to joining nodes.
# Depends on SST method. For mysqldump method it is root:<root password>
wsrep_sst_auth=root:
# Desired SST donor name.
#wsrep_sst_donor=
# Reject client queries when donating SST (false)
#wsrep_sst_donor_rejects_queries=0
# Protocol version to use
# wsrep_protocol_version=
Creating the Cluster DB Filestructure
Once you have configured your primary node or ‘first node’, in this case as this is a set of 3 ‘masters’ all can be written and sync with eachother. You will need to run the shell command galera_new_cluster.
[adam@galera-1 my.cnf.d]$ galera_new_cluster
Configure the other nodes in cluster with the same configuration file
Now we will need to configure the other 2 nodes ‘galera-2’ and ‘galera-3’ respectively. Making sure to give them a human readable name ‘wsrep_node_name=’ you don’t have to do it, but please do it. Your crazy running a big cluster without that and you can see why this is once you start the cluster.
Starting the Cluster
It’s important to start the cluster after the initial cluster has been created on a given node; i.e using the galera_new_cluster is defining ‘I am the copy to sync to the other nodes’. An initiatialisation state, in this configuration all the nodes will sync with eachother as data is written to any of them once this initial stage is completed.
We will check the status of the nodes using systemctl
[adam@galera-1 my.cnf.d]$ sudo systemctl status mariadb
● mariadb.service - MariaDB 10.11 database server
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; preset: disabled)
Active: active (running) since Sat 2024-02-24 11:46:05 EST; 9s ago
Docs: man:mariadbd(8)
https://mariadb.com/kb/en/library/systemd/
Process: 8105 ExecStartPre=/usr/libexec/mariadb-check-socket (code=exited, status=0/SUCCESS)
Process: 8127 ExecStartPre=/usr/libexec/mariadb-prepare-db-dir mariadb.service (code=exited, status=0/SUCCESS)
Process: 8364 ExecStartPost=/usr/libexec/mariadb-check-upgrade (code=exited, status=0/SUCCESS)
Main PID: 8162 (mariadbd)
Status: "Taking your SQL requests now..."
Tasks: 17 (limit: 10856)
Memory: 179.1M
CPU: 903ms
CGroup: /system.slice/mariadb.service
└─8162 /usr/libexec/mariadbd --basedir=/usr
Feb 24 11:46:04 galera-1 rsyncd[8323]: sent 2005 bytes received 416901 bytes total size 408076
Feb 24 11:46:04 galera-1 rsyncd[8329]: connect from galera-2 (192.168.122.199)
Feb 24 11:46:04 galera-1 rsyncd[8329]: rsync allowed access on module rsync_sst from galera-2 (192.168.122.199)
Feb 24 11:46:04 galera-1 rsyncd[8324]: sent 48 bytes received 386 bytes total size 65
Feb 24 11:46:04 galera-1 rsyncd[8322]: sent 48 bytes received 383 bytes total size 67
Feb 24 11:46:04 galera-1 rsyncd[8329]: rsync to rsync_sst/ from galera-2 (192.168.122.199)
Feb 24 11:46:04 galera-1 rsyncd[8329]: receiving file list
Feb 24 11:46:04 galera-1 rsyncd[8329]: sent 48 bytes received 185 bytes total size 41
Feb 24 11:46:05 galera-1 rsyncd[8294]: sent 0 bytes received 0 bytes total size 0
Feb 24 11:46:05 galera-1 systemd[1]: Started MariaDB 10.11 database server.
We can see that our first node is receiving from galera-2.
We can also see that our 3rd node is communicating with galera-1
[root@galera-3 my.cnf.d]# systemctl status mariadb
● mariadb.service - MariaDB 10.11 database server
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; preset: disabled)
Active: active (running) since Fri 2024-02-23 21:08:45 EST; 14h ago
Docs: man:mariadbd(8)
https://mariadb.com/kb/en/library/systemd/
Main PID: 14265 (mariadbd)
Status: "Taking your SQL requests now..."
Tasks: 17 (limit: 10857)
Memory: 257.0M
CPU: 37.386s
CGroup: /system.slice/mariadb.service
└─14265 /usr/libexec/mariadbd --basedir=/usr
Feb 23 21:08:43 galera-3 rsyncd[14426]: sent 2005 bytes received 416977 bytes total size 408076
Feb 23 21:08:43 galera-3 rsyncd[14424]: sent 1853 bytes received 4052436 bytes total size 4045370
Feb 23 21:08:43 galera-3 rsyncd[14430]: connect from galera-1 (192.168.122.219)
Feb 23 21:08:43 galera-3 rsyncd[14430]: rsync allowed access on module rsync_sst from galera-1 (192.168.122.219)
Feb 23 21:08:43 galera-3 rsyncd[14425]: sent 48 bytes received 380 bytes total size 67
Feb 23 21:08:44 galera-3 rsyncd[14430]: rsync to rsync_sst/ from galera-1 (192.168.122.219)
Feb 23 21:08:44 galera-3 rsyncd[14430]: receiving file list
Feb 23 21:08:44 galera-3 rsyncd[14430]: sent 48 bytes received 186 bytes total size 41
Feb 23 21:08:44 galera-3 rsyncd[14397]: sent 0 bytes received 0 bytes total size 0
Feb 23 21:08:45 galera-3 systemd[1]: Started MariaDB 10.11 database server.
Lets install sysbench to run some performance tests of our new cluster against the nodes. This is pretty important and will reveal any bottlenecks or serious misconfiguration that results. Naturally the query size and type of queries matter too, but that is often to do with application design, rather than the physical set up of the application. Though depending on the application tuning can be done and then tests can be repeated with the application in staging, or utilising a specific sysbench query with given query size/test data etc.
# sys bench is in the epel-release repo so lets install it
dnf install epel-release
dnf install sysbench
Tuning Sysctl, threading, tcp_wait maxconn and more
So, although this is a virtualised cluster, and because each machine is virtualised by the same file system limitations set by the hypervisor, the performance increase is minimal, since, most of the writing is made to disk, and a shared disk means that having your cloud nodes on the same hyperivsor for a cloud galera cluster is very very bad indeed.
[adam@galera-1 my.cnf.d]$ sysbench oltp_read_write --table-size=1000000 --db-driver=mysql --mysql-db=test --mysql-user=root --mysql-password=test --threads=2 --mysql-host=192.168.122.219,192.168.122.247,192.168.199 run
sysbench 1.0.20 (using system LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 31360
write: 7999
other: 5438
total: 44797
transactions: 2237 (223.52 per sec.)
queries: 44797 (4476.08 per sec.)
ignored errors: 3 (0.30 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0063s
total number of events: 2237
Latency (ms):
min: 3.67
avg: 8.94
max: 24.25
95th percentile: 13.95
sum: 20002.45
Threads fairness:
events (avg/stddev): 1118.5000/60.50
execution time (avg/stddev): 10.0012/0.00
In reality, a galera cluster could be 3 bare metal servers, or 3 cloud instances on seperate hypervisors making full use of the IOPS available (writes/reads) on each device attached to each node. So, although we won’t see much difference in our sysbench marks because of the virtual synthetic lab I have created. I still think it is really important to cover sysctl tuning et al.
So lets first increase the maxconns that Mariadb can do, and increase the size of the innodb log from 100M to 2000M, and the maxconnections to 3000 each. Whilst we’re at it lets also increase the number of threads for the galera cluster slaves from 1 to 32. This is pretty important as its effectively the number of sharding instances assigned per query-set grouping from my understanding. Let’s do it!
MariaDB [(none)]> SHOW GLOBAL VARIABLES LIKE 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 3000 |
+-----------------+-------+
1 row in set (0.001 sec)
Let’s take a look at the mysql database of the cluster and inspect the wsrep_cluster; and verify that the members really are working correctly with each node incoming_address forwarding as it should; this is important for the distribution of load between the cluster.
Perfect, so everything is there, but I’d expect to see a little better performance, so let’s set some sysctl defaults, because the ones on these VM’s is going to be really low and TCP_WAIT on 128 threads is really miniscule
These values need to really be a lot higher for us to hit the real bottleneck, which is a lot higher as a ‘hard’ limit than these ‘soft’ limits set in the VM are imposed. So lets go ahead and put in some new sysctl tunables on all of our VM’s as follows;
vim /etc/sysctl.conf
[adam@galera-1 ~]$ sudo vim /etc/sysctl.conf
[adam@galera-1 ~]$ cat /etc/sysctl.conf
# sysctl settings are defined through files in
# /usr/lib/sysctl.d/, /run/sysctl.d/, and /etc/sysctl.d/.
#
# Vendors settings live in /usr/lib/sysctl.d/.
# To override a whole file, create a new file with the same in
# /etc/sysctl.d/ and put new settings there. To override
# only specific settings, add a file with a lexically later
# name in /etc/sysctl.d/ and put new settings there.
#
# For more information, see sysctl.conf(5) and sysctl.d(5).
#
#
# Increase the maximum number of memory map areas a process may have
# This can help prevent out-of-memory errors in large applications
vm.max_map_count=262144
# Increase the maximum number of file handles and inode cache for large file transfers
# This can improve performance when dealing with a large number of files
fs.file-max = 3261780
# Increase the maximum buffer size for TCP
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
# Increase Linux autotuning TCP buffer limits
net.ipv4.tcp_rmem = 4096 12582912 16777216
net.ipv4.tcp_wmem = 4096 12582912 16777216
# Disable caching of ssthresh from previous TCP connection
net.ipv4.tcp_no_metrics_save = 1
# Reduce the kernel's tendency to swap
vm.swappiness = 1
# Set the default queueing discipline for network devices
net.core.default_qdisc = fq_codel
# Enable TCP BBR congestion control
net.ipv4.tcp_congestion_control=bbr
# Enable TCP MTU probing
net.ipv4.tcp_mtu_probing=1
# Increase the maximum input queue length of a network device
net.core.netdev_max_backlog = 32768
# Increase the maximum accept queue limit
net.core.somaxconn = 65535
# Reduce the number of SYN and SYN+ACK retries before packet expires
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
# Reduce the timeout to close client connections in TIME_WAIT state
net.ipv4.tcp_fin_timeout = 30
# Disable SYN cookie flood protection
net.ipv4.tcp_syncookies = 0
# Increase the local port range used by TCP and UDP
net.ipv4.ip_local_port_range = 1024 61000
# Additional Galera Cluster optimizations
# Increase the number of allowed open files per process for MariaDB
fs.file-max = 100000
# Increase the number of file handles specifically for MariaDB
# Adjust according to the needs of your Galera Cluster
fs.aio-max-nr = 1000000
And be sure to run this afterwards so that sysctl runs the present configuration
sysctl -p
Let’s rerun our test using all 32 threads, which was failing before from timeouts [due to too many threads overwhelming the sysctl limits set in sysbench’s shell we’re testing from]
The error we were getting :
[adam@galera-1 ~]$ sysbench oltp_read_write --table-size=1000000 --db-driver=mysql --mysql-db=test --mysql-user=root --mysql-password=test --threads=16 --mysql --host=192.168.122.219,192.168.122.247,192.168.199 run
sysbench 1.0.20 (using system LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 16
Initializing random number generator from current time
Initializing worker threads...
FATAL: Worker threads failed to initialize within 30 seconds!
After we have increased the limits on mariadb galera, and sysctl we can rerun the test to get maximum throughput (
[adam@galera-1 ~]$ sysbench oltp_read_write --table-size=1000000 --db-driver=mysql --mysql-db=test --mysql-user=root --mysql-password=test --threads=16 --mysql-host=192.168.122.219,192.168.122.247,192.168.122.199 run sysbench 1.0.20 (using system LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 16
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 204624
write: 52222
other: 35396
total: 292242
transactions: 14555 (1453.33 per sec.)
queries: 292242 (29180.70 per sec.)
ignored errors: 61 (6.09 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0131s
total number of events: 14555
Latency (ms):
min: 3.62
avg: 11.00
max: 123.99
95th percentile: 15.83
sum: 160056.66
Threads fairness:
events (avg/stddev): 909.6875/105.22
execution time (avg/stddev): 10.0035/0.01
Wow! What a difference, we have nearly quadrupled the read performance now by taking all of these steps. I am really impressed with the results. Though this hypervisor is utilising NVME, so I would ideally expect to see writes in the 1GB/s to 6GB/s range at least! I think though, that it depends on how the queries are bulked together, and the delay in each transaction sent to and from the cluster and disk. Also, we have to bare in mind that these aren’t baremetal benchmarks either. Lets run hdparm and see what libvirt can do anyways.
[adam@galera-1 ~]$ sudo fdisk -l
Disk /dev/vda: 10 GiB, 10737418240 bytes, 20971520 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xdce436c4
Device Boot Start End Sectors Size Id Type
/dev/vda1 * 2048 20971486 20969439 10G 83 Linux
[adam@galera-1 ~]$ hdparm -Tt /dev/vda1
/dev/vda1: Permission denied
[adam@galera-1 ~]$ sudo hdparm -Tt /dev/vda1
/dev/vda1:
Timing cached reads: 21602 MB in 1.99 seconds = 10856.33 MB/sec
Timing buffered disk reads: 6226 MB in 3.00 seconds = 2074.76 MB/sec
Woof. I really love my HP Z440. With those 16 cores and 32 threads and a 10GB/s pci busspeed it leaves nothing much to be more desired. I think that with some more effort , perhaps by increasing the number of CPU cores and ram of the Galera Cluster we could get this far beyond 15k/qps which is pretty impressive for a single server machine. I am going to run some benchmark against mariadb on the hypervisor on the bare metal and see how much efficiency is really lost in splitting it between these 3 instances. However, if this was 3 dedicated machines, I am confident the results would be pretty amazing.
I think I could probably loosen the consistency restraints so that others worked as slaves rather than synchronous masters, and get a lot more than 15k qps.
With 32 threads we see even better performance.
[adam@galera-1 ~]$ sysbench oltp_read_write --table-size=1000000 --db-driver=mysql --mysql-db=test --mysql-use r=root --mysql-password=test --threads=32 --mysql-host=192.168.122.219,192.168.122.247,192.168.122.199 run
sysbench 1.0.20 (using system LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 32
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 275352
write: 70394
other: 47423
total: 393169
transactions: 19513 (1948.12 per sec.)
queries: 393169 (39252.79 per sec.)
ignored errors: 155 (15.47 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 10.0145s
total number of events: 19513
Latency (ms):
min: 4.75
avg: 16.41
max: 121.10
95th percentile: 26.68
sum: 320136.02
Threads fairness:
events (avg/stddev): 609.7812/98.11
execution time (avg/stddev): 10.0043/0.00
Likely there are a lot more things I can do to increase performance and make use of the nvme backed virtio disk, however because all the instances are on the same box hypervisor lab theqps is lower that it would otherwise be in a real production setting, which is important to consider.
Anyways, that’s all folks! Hopefully I will get time to automate this with ansible on the local hyperivisors adam user and build a little automation script that puts together libvirt vm creation and the configuration of all described above into a single script. And maybe as an added bonus we could add in some sysbench tests and return codes from the playbook, which might be with some adaptation really handy for testing out database implementations on different cloud providers.
Last but not least! Lets make it so that mariadb [galera] is running on boot, do this on all machines;
Python3 has a very neat library in it that will save you a lot of unnecessary heavy lifting processing and re-engineering your average web 2.0 json output api. It’s pretty neat how if you know what your doing not only can you implement a really cool monitoring API (not that you’d need to there are plenty of 3rd party ones available like newrelic, datadog and many others), but perhaps you may have proprietary reason to develop your own internal monitoring, and various other reasons.
Also, when it comes to monitoring server side processes, states with application layers or microservices there is more going on in the middleware, but it’s exactly the same process except in your app.get you are going to define a function that checks for output or inputs of another program, and so on, be that a datastore, text file, api call, or conditional developing API with python is made really easy. We will use uvicorn to run the python-server.
import uvicorn
import os
import psutil
from fastapi import FastAPI
We also are using the fastapi library to generate our arbitrary server calls for the client. We use os,psutil to access certain os functions for the other calls.
We might be using the API call for our own custom service tracker, trigger alarm, alert, such as if bruteforcing etc is happening maybe the trigger that consumes this alarm can set an upper limit or range for its rate_of_change and so on. This simply provides output for the number of requests made. A seperate read_only function could be made that only reads the variable by removing hits+=1.
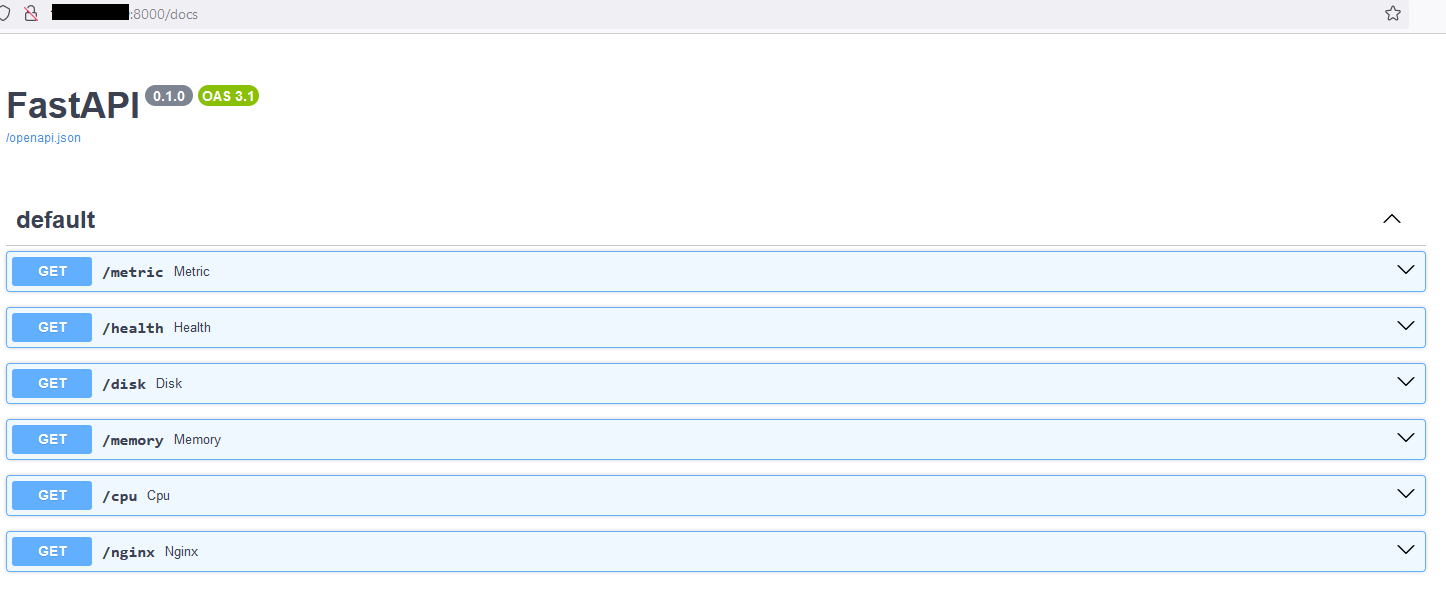
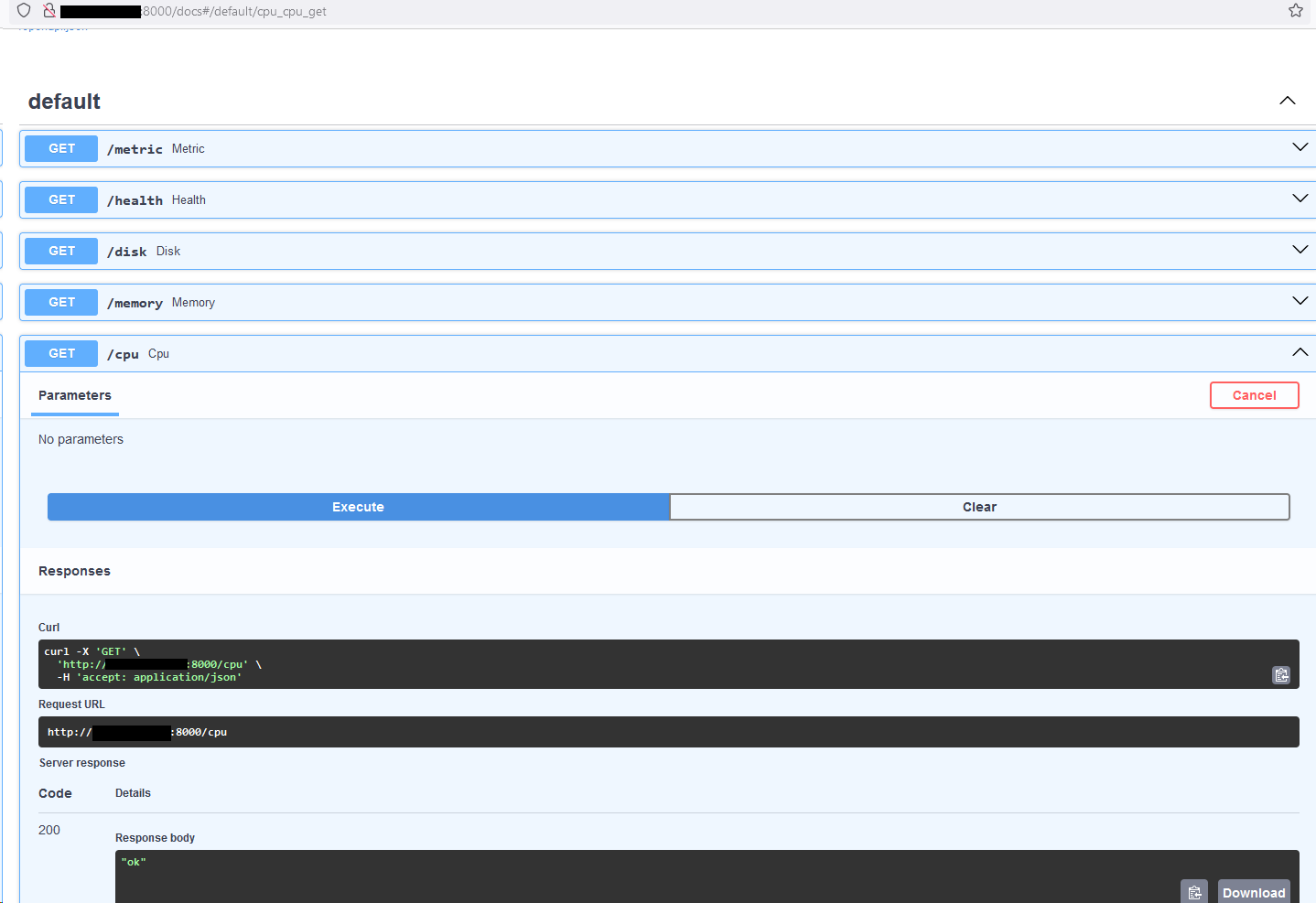
/health
A pretty standard thing for any monitoring APi is the health endpoint, normally an “true” or “OK” statement string suffices, but some people run much more conditional health that could check an array of resources or other api endpoints values before returning the client output. I haven’t done lots of development with Python but it seems like a pretty cool language worth time, and with Flash and uvicorn a pretty compelling usercase exists for rapid prototyping and development.
I thought it would also be cool to try my hand at writing a basic disk metric. I am not sure if this was the best way to implement it and it is kind of hacky, you may not want to monitor /, but a specific path with a specific disk which is simple enough to do by altering the statement to reflect the path.
## while we're at it lets generate /memory and /cpu metrics too cause its really easy todo
@app.get("/memory")
async def memory():
# Getting % usage of virtual_memory ( 3rd field)
current_mem_used = psutil.virtual_memory()[2]
print(current_mem_used)
if current_mem_used < 90:
return "ok"
else:
return "not ok"
@app.get("/cpu")
async def cpu():
# should probably use aggregates for loadavg perhaps
current_cpu_used = psutil.cpu_percent(interval=10)
max_percent_load = 90
print(current_cpu_used)
if current_cpu_used < max_percent_load:
return "ok"
else:
return "not ok"
Example of Service Status endpoint for Nginx
Since I was at it I thought it worthwhile to spend a few minutes creating an arbitrary and hopelessly basic check of nginx using psutil. I am wondering if it is better to use systemctl status output or some other library instead, I don’t like using unnecessary libraries though unless it is making things a lot less convuluted by doing that.
# we need this helper function to get process matching for a given service as an argument
def is_process_running(name):
for process in psutil.process_iter(['name']):
if process.info['name'] == name:
return True
return False
# with the above helper function we can use this simple notation for all desired processes
@app.get("/nginx")
async def nginx():
if is_process_running('nginx'):
return "ok"
else:
return "bad"
Starting the API Service application
Much like with nodejs and scala its a pretty simple framework/lib to deploy to a server, just append this to the bottom of your python file and then execute as normal.
if __name__ == '__main__':
uvicorn.run(app, host="0.0.0.0", port=8000)
python3 monitor-api-service.py
Let’s go ahead and open up this in a browser by navigating to http://ipofserver:8000
Pretty neat. Note this is running as http:// to run as https:// you will need a certificate and to define it like
In this case because the HTTPS transport and cert are a seperate layer to the plaintext api they aren’t really anything to do with the implementing of the API itself and moreover to do with termination of the TLS certificate at the tld, in any case perhaps you want to implement properly with https. You can get free certs from letsencrypt using the certbot commandline utility.
The power of developing api rapidly like this is really eye-changing for anyone who had a complex server or rpc service backend, as perhaps they’ll see that they only need only translate the necessary command functions with such approach to provide nearly any data thru the api from any service or corresponding conditional test.
Producing something like this is easy but doing it correctly in the first place will always be the real challenge.
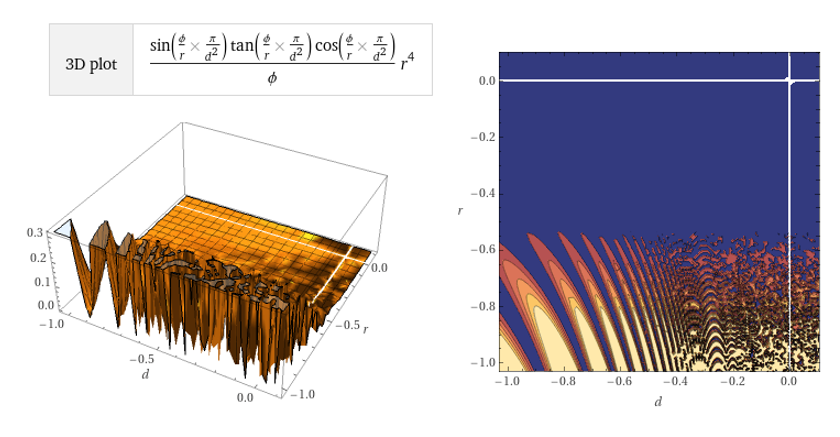
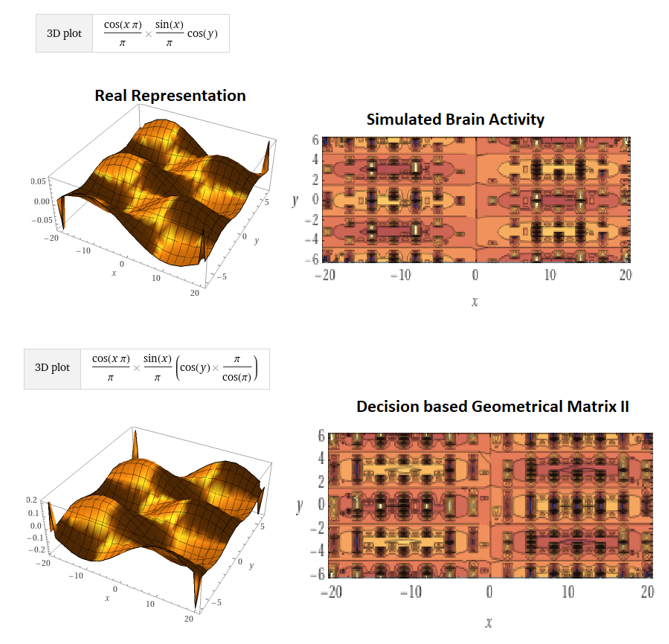
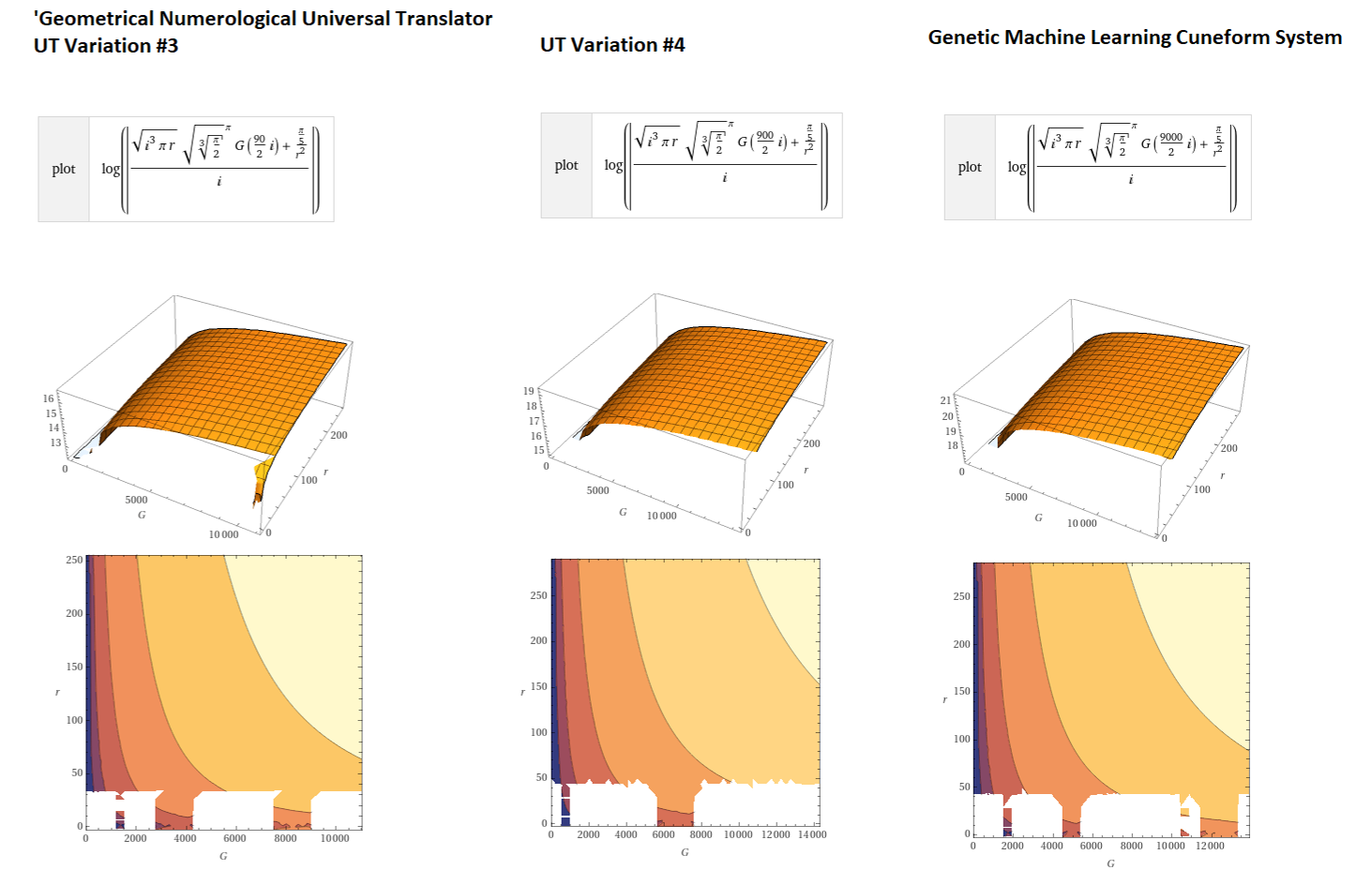
Greetings, for those who know me my quiet (but probably quite extensive) interest in data theory has been brewing in my latest fun-but-semi-commercial project, cosmic OS, among them generative computation, fascinating to me as a musician and also a technical engineer I’ve watched over the last 20 years what were previously far away pipe-dreams and ludicrous ideas are becoming increasingly probable computationally, as mathematical and computer modeling systems evolve substantially. Some of these concepts seem important for bio feedback and development of neural interface but it beyond the scope of this article. I will include more details about the increasingly theoretical probabilistic neural interface in my next post.
Although my technical researches and hobby interests in sub space field mechanics and imaginary and real complex planes has been a generally a private interest some of the more recent invokations of AI and ML, in particular generative adversarial networks have started to support some of my earlier ideas and conclusions about generative computation and the square root of -1 in relation to m-verse theory, quantum computation and intelligent systems. We are approaching computer systems that can explore for us, and, eventually with us in fascinating ways never conceived before. There is some engineering and computational gaps that exist in this market but I have found it interesting enough to devote large amount of my own computational time to map some of what I believe will be important ideas for investors, engineers and businesses in the next 20 years as this revolution stands to shake the foundation of computation as we know it.
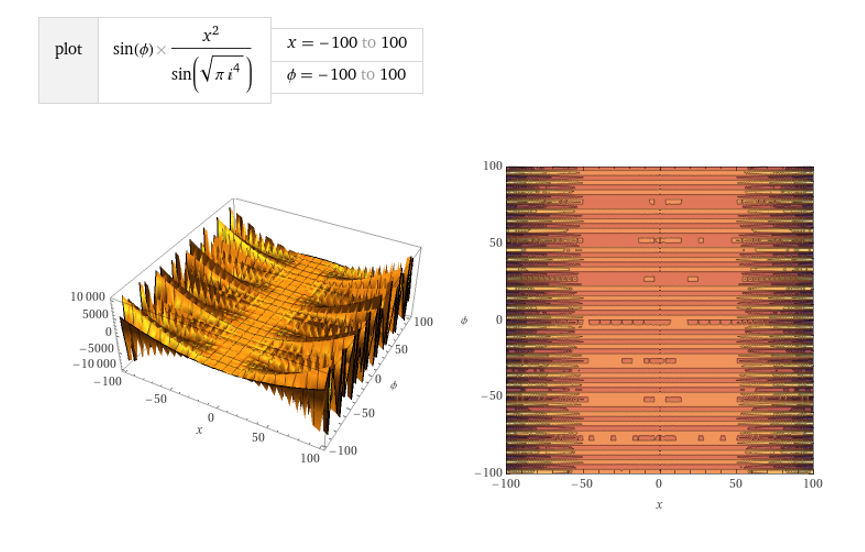
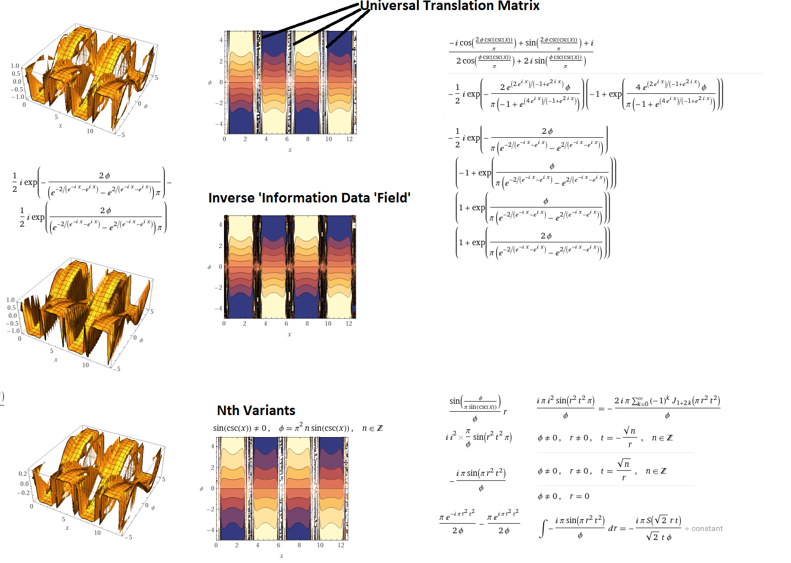
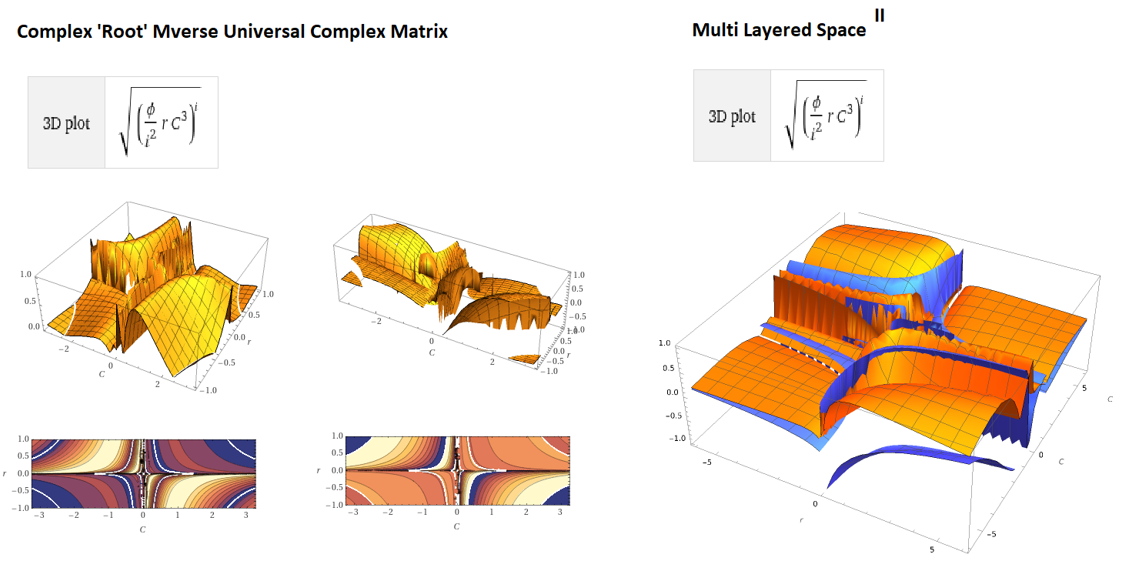
Generating nth term variations of complex imaginary planes from pi phi and sqrt-1
Now, adversarial discriminatory instruments and source code repositories are widely available thru nvidia, gpt and many others which utilise high speed ASIC to carry out high performance computational at a great scale. One natural extension of mining is previous research applications into company resource, such as cloud, and beyond transnational trade and intercorporate co-operation at a block chain ledger level (or in other words blockchain securities and cloud). Although I have been engaged in professional interests such as developing blockchain applications for IPFS and Ravencoin and exchange software for the future of transnational securities, these technical, computational and organisational changes of the market sector has been something I predicted long ago, before cloud and blockchain.
One way of looking at the bizarre theory is that computers are engineered to only have one way of looking at things or one output or ‘perspective’, however with quantum computers many more inputs and outputs can be enumerated effectively creating inconceivably complex and recursive depth. We might expect the next generation of gan to have a multi-dimensional logic and intelligence that surpasses current engineering principles utilised presentlyin ray tracing, computational analysis etc completely changing the predictive and creative processes and our relationship with these systems. Certainly for this researches we are interested and fascinated with how human perception and behaviour form and emerge in order to create an engineered analogue of the same
In the early days when divx 3.11 was still new, I remember seeing the possibilities of youtube and netflix, but this feels exponents way bigger in scope. That said the once ceo of google mr schmidt (hope I spelled this correctly) the ability to execute in bulk has become more important in todays modern age than the ability to innovate and invent.
The situation with AI and ML is that it may become in the not so distant future much more important to innovate thru execution of AI and ML processes, which represent in business terms a major change ahead for the world as hybrid machine learning computational systems furnish augmentations to user level behaviour, which organisations that cannot adapt to the increase in tooling, innovation and computational power may perish to. This probably has fascinating social implications but it’s well beyond the scope of this piece. I shall focus on some of these wonderful equations as we try and expand our imagination into 3 dimensional and 4 dimensional generative adversarial relational computation. Certainly we may expect to see an AI and ML black box physicist telling us impossible things about these beautiful relationships that we could not even possibly comprehend or resort to time ofe centuries to discover.
Their stems understandable if not valid reason why there is some measure of concern by the crowd and governance to stem the growth of systems which are beginning to mimic consciousness and intelligent systems in a way that is convincing, which has wide implications for how it will alter human capability and behaviour in the market place. Again it’s really beyond the scope of the piece but we’re interested in food for a computer system that can imagine and we can do this convincingly with generative adversarials because they are not ordinary input and outputs, in fact they re-use outputs to increase the resolution of modeling in a convincing way not dissimilar from human beings. Still as a man who foresee’s power as a measure of universal computational ability in the not so distant future, the social and economic implications are of pretty huge interest if not total fascination to me.
If people understand what this really means, they should get excited! I think! Therefore I Infinite GAN Nourishment!
Moreover the massive expansion in gpu and high performance computation, in particular fixed bus width quantum computers has some dizzying applications for the generative adversarial networks of the future both for use in the financial backtesting and predictive systems. They probably represent a new meta for trading, computation and generative simulation of the future, substantially beyond an order of magnitude ahead, redefining the usual static outputs available in programmatic computation , ray tracing and statistical analysis today, reducing latency of computational to null for inconceivably complex plane solutions, and reshaping the meaning(and limitations) of a computational system we presently know. As – much like human beings, quantum computers will have adequate infinite cycles at a fixed bus width, therefore the computer of tomorrow will look more like a GAN of nearly infinite inputs and reasuable modular outputs in many different factories or ‘faculty’ of ‘cloud idea’ as ‘pools. Then one might expect, perhaps, all those extra cpu cycles, machines will need to ‘learn’ to dream to make good use of the extra cycles and lower latency to gain efficiency of their advantage.
Therefore, In order to plan for such an eventuality the engineer, inventor and ‘musician’ must create the necessary equations to feed such a computationally vast processor, and develop further a working theory of emergent intelligence by mapping human behaviours sufficiently for their recreation etc.
Computational Glyph Searching, a Theoretical Concept introduced in cosmicOS
One approach for nourishment of such an increasingly hypothetical array is the complex imaginary component also known to mathematicians as the square root of -1, whereby a single system or symbolic understanding of related data or informational knowledge can be recursively computed although at fixed bus widths in quantum processors infinite cycles per second, will produce a multitude and magnification of the available computational power and for drawing and navigating intelligence around complex diagrams and performing even more complex discriminations, approaching what we might refer to as the singularity in modern literature, but moreover and most importantly approaching an infinite recursion or divide by zero as the input and ouput cycles on such a hypothetical system as cosmic OS, begin to do more than merely mimic the activities of human inputs and outputs, but evolve with recursive input and outputs which eventually form independent systems which may match or exceed human ability. Naturally such a theory represents great interest to me both as an business minded individual and as a person with a deep interest in distributed computation, generative systems and AI.
CosmicOS has been a labor of love and although ambitious I can see and feel it’s potential. A real engineer wants not just to produce something fantastical and in this case nearly impossible, he wants the research or idea to imbibe meaning and have an impact on others imagination not only to remind him and encourage him that his ideas may have promise or to develop them, or be recognised that his predictions merit, but so that he can see it benefit folks in a beneficial way. A lot of the inventors of the most amazing things don’t receive the credit, and in my estimation probably don’t want it either. I think that’s because most of those folks aren’t just trying to get respect or understanding. They are trying to make the world better, increase human energy and imagination and the only way they can do that is by risking to imagine tomorrow in new impossible and creative ways.
I felt it was time to share more about what I’ve been doing with the possibilities of producing adversarial networks capable of producing large chains of inputs and outputs, and nourishing data of infinite recursive complexity, much like the human brain, since technology has probably caught up enough for people to see the theoretical possibility, and reduced theoretical impossibility of producing all 2^52 combinations for an audio CD for the purpose of universal exploration, researches, ray tracing. Really the goal will be how to sort the data effectively and indeed for sanity and storage purposes recreate nth partition sector of storage programatically using computation rather than a disk- i loosely will term this algorithmic storage – but its a bit too futuristic to encourage others to give it serious thought yet, perhaps.
The applications really are mind boggling and endless for anyone who can understand them. Our biggest problem may be feeding AI and ML Systems, or showing them how to create data to feed them indefinitely would be ideal. Though – if people understood these things better and the things human beings produced and the way the parts that make them up produced them, conscious computer systems would have already been considered long ago as an emergent property of quantum physics and integrated relativistic dimensions of space time.
From mathematical and statistical perspective adversarial applications for deep learning seem substantial
Conclusion – CosmicOS predicates a machine that can observe and reobserve discriminately and reprocess outputs as new inputs to develop ‘pools’ or ‘organs’ of relational intelligence
That kind of predicts a new type of database system collation required to adequately map human memory and creativity! whew! I hope that this provides some insight into the possibilities of GAN, and that it is as always with this industry – still really early in its adoption but it has been making me think a lot about how strange the future will be as computers gain these capabilities.
These developments are not just worthwhile to significantly improve human capability and scientific engineering, but have genuine artistic, scientific and creative applications that will likely one day go far beyond the human imagination. Fortunately today at least people can see these engineering ideas which were predicted hundreds if not thousands of years ago because the technology is finally available to be convincing that people can really see the benefits. Whilst many focus on the drawbacks and danger of machines I feel that it is human beings investments and interests that influence their decisions. These computer systems , theoretical as they may be, I can see will one day be clearly capable of influencing us in ways even I can’t imagine, and I wonder what kind of world that will be. And whether these are issues of human morality and virtue or something deeper as to the complexity of our universe. Whichever is true I shall be equally astonished in my equanimity and enjoyment of these equations and myriad possibilities for the future. So, I suppose an enterprising person then may benefit from acting accordingly on this knowledge in his researches and adventures.
It’s good to keep dreaming and find new ways to express ideas in new projects like cosmic OS. It’s the most fun I’ve had in years.
The ideas are pretty far out for cosmic OS but their ambitiousness is not without some technical meat. The equations work. Is that what matters? yes. It’s probably important that people understand what a GAN is and what try {01} for all parts of a given spacial area represents for a recursive model. It’s… beyond even me, that is why I am so interested in it, but I see the possibilities and it feels good to encourage others and talk more about some of my fun-semi-commercial researches.
Thanks for Reading
Cosmic OS is something I’ve been musing over for decades. Since I first started using distributed compute. I thought it was time to talk a bit more about the idea, and possibly be lambasted for it, but if you don’t take the risk of being wrong you never take the risk of being right. That to me personally has always seemed like too significant a risk of missing. The path of creativity and impossible ambition is the road less voyaged, but one cannot achieve something so ambitious without taking such improbable decisions and calculations with just being ambitious and seeing where it will lead.
I developed a universal translator system that learned languages that don’t exist using the square root of -1. Here is one impossible theoretical diagram for the day. So, I don’t know where a lot of my more unusual ideas come from, but that is another conversation to have probably, the important thing is that the equations matter that prove the discrimination of algorithm is there for discriminated AI/ML output? right? right?
Perhaps.
As an engineer it seems that it well beyond our undertanding of computation presently to really understand what these implications are. Certainly it is a marvelous thing to produce ancient languages from the imaginary complex plain (much like producing audio conversations of caesar) without being there, never needing to leave ones home or rack of computational machinery, with sufficient processing power and storage beyond the number of atoms visible in the universe, it would be a simple matter of known physical engineering to achieve. Despite that it would take several universes to find the conversation, a GAN, and algorithmic finding discovery represent the new brute force generative discriminator adaptor to building new intelligent analysis networks and models far beyond what we have ever conceived. I don’t think I’ll be the guy to do that, but if someone likes the idea there is always a foot note below your project for the credit of the idea.
I’ve been trying out the trial of Wolfram Mathematica as part of my research into cosmic OS and creating a generative universe from the square root of -1 and other interesting things. In this example I’m generating some waves and altering a given component of the equation to provide frame by frame output of the plot. It’s really neat and I am having a lot of fun with it.
I noticed their documentation is pretty useful at documenting each function but you have to do a bit of effort to understand properly how to plot into export directly. The two choices available seem to be a frame by frame fps ‘da’ variable, the other by calling AnimationDuration->15, notice also in this example imageresolution and antialiasing are set, ImageResolution -> 800, Antialiasing -> True, this overides the default animation setting, which for our purposes is too small for a large range of variable sine wave ‘a’.
Stuff like this makes me really happy, and will be a perfect approach in the meantime for some of our renders for Cosmic OS.