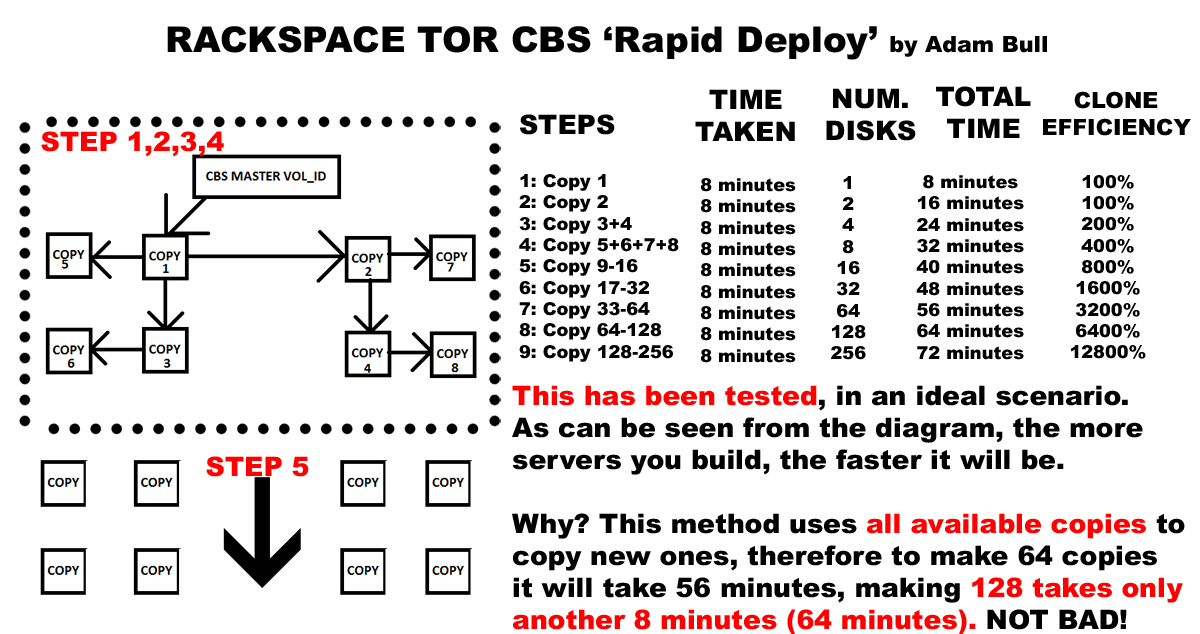
Hey folks. So, recently I have been doing a bit of work on the Rackspace community, specifically trying to document and make as easy as possible the importing and exporting of cloud server VHD’s between Rackspace regions. This might be really useful if you are designing some HA or multi-region and/or load balancing solution that might be utilizing autoscale, and other kinds of redundancy too, but moving your ‘golden image’ between regions might be quite difficult if doing the entire process manually or step by step as I have documented in the below two articles:
Exporting Cloud server images from a Rackspace Region https://community.rackspace.com/products/f/25/t/7089
Importing Cloud Server Images to a Rackspace Region https://community.rackspace.com/products/f/25/t/7186
In this article I completely finish writing the ‘automation demo’ of how to specifically move images, without changing much at all, apart from one ‘serverID’ variable, and the source and destination. The script isn’t finished yet, however the last time I posted this on my blog I was so excited, I actually forgot to include the import function. (which is kind of important!) sorry about that.
#!/bin/bash
USERNAME='yourmycloudusernamehere'
APIKEY='youapikeyhere'
API_ENDPOINT='https://lon.servers.api.rackspacecloud.com/v2/1000000'
SERVER_ID='94157dc7-924a-424a-8825-c5ffbd341622'
TENANT='1000000'
CUSTOMER_ID='1000000'
#### DO NOT CHANGE BELOW THIS LINE
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
# START IMAGE CREATION
echo "Creating Image at Local Datacentre"
curl -v -D export-headers \
-H "X-Auth-Token: $TOKEN" \
-H "Accept: application/json" \
-H "content-type: application/json" \
-d '{"createImage" : {"name" : "RA-'$SERVER_ID'", "metadata": { "ImageType": "Rackspace Automation Image Exported from '$TENANT'", "ImageVersion": "2.0"}}}' \
-X POST "$API_ENDPOINT/servers/$SERVER_ID/action" -o /tmp/export-file
echo "export headers"
cat export-headers
# Retrieve correct ImageID and use to check status of image
IMAGEID=$(cat export-headers | grep -i location | sed 's/\// /g' | awk '{print $7}')
sleep 5
echo "image id"
echo $IMAGEID
API_ENDPOINT='https://lon.images.api.rackspacecloud.com/v2/images/'
URL=$API_ENDPOINT$IMAGEID
URL=${URL%$'\r'}
curl -v \
-H "X-Auth-Token: $TOKEN" \
-H "X-Project-Id: 1000000" \
-H "Accept: application/json" \
-H "content-type: application/json" \
-X GET "$URL" | python -mjson.tool > imagestatus
echo "imagestatus: $imagestatus"
STATUS=$(cat imagestatus | grep status | awk '{print $2}' | sed 's/"//g' | sed 's/,//g')
## WAIT FOR IMAGE TO EXIT SAVE STATE
echo "Waiting for image to complete..."
sleep 5
while [ "$STATUS" != "active" ]; do
echo "image $IMAGEID is still saving..."
sleep 10
curl -s \
-H "X-Auth-Token: $TOKEN" \
-H "X-Project-Id: 1000000" \
-H "Accept: application/json" \
-H "content-type: application/json" \
-X GET "$URL" | python -mjson.tool > imagestatus
STATUS=$(cat imagestatus | grep status | awk '{print $2}' | sed 's/"//g' | sed 's/,//g')
done
## PREPARE/CREATE CLOUD FILES CONTAINER for EXPORT
echo "Preparing/Creating Cloud Files Container for Export"
API_ENDPOINT='https://storage101.lon3.clouddrive.com/v1/MossoCloudFS_1000000'
curl -v -s \
-H "X-Auth-Token: $TOKEN" \
-H "X-Project-Id: 1000000" \
-H "Accept: application/json" \
-X PUT "$API_ENDPOINT/export"
sleep 5
## EXPORT VHD TO CLOUD FILES
echo "Exporting VHD to Cloud Files"
# This section simply retrieves the TOKEN
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
echo "IMAGEID detected as $IMAGEID"
# This section requests the Glance API to copy the cloud server image uuid to a cloud files container called export
# > export-cloudfiles
echo "THE IMAGE ID IS: $IMAGEID"
IMAGEID=${IMAGEID%$'\r'}
curl -v "https://lon.images.api.rackspacecloud.com/v2/$TENANT/tasks" -X POST -H "X-Auth-Token: $TOKEN" -H "Content-Type: application/json" -d '{"type": "export", "input": {"image_uuid": "'$IMAGEID'" , "receiving_swift_container": "export"}}' -o export-cloudfiles
echo "Export looks like"
cat export-cloudfiles
sleep 15
echo "export cloud-files looks like:"
cat export-cloudfiles
TASKID_EXPORT=$(cat export-cloudfiles | python -mjson.tool | grep '"id"' | awk '{print $2}' | sed 's/"//g' | sed 's/,//g')
echo "task ID export looks like"
echo "$TASKID_EXPORT"
API_ENDPOINT='https://storage101.lon3.clouddrive.com/v1/MossoCloudFS_1000000'
sleep 15
echo "Waiting for Task to complete..."
## WAIT FOR TASKID EXPORT TO COMPLETE TO CLOUD FILES
# This section simply retrieves the TOKEN
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
# This section requests the Glance API to copy the cloud server image uuid to a cloud files container called export
curl "https://lon.images.api.rackspacecloud.com/v2/1000000/tasks/$TASKID_EXPORT" -X GET -H "X-Auth-Token: $TOKEN" -H "Content-Type: application/json" | python -mjson.tool > export-status
EXPORT_STATUS=$(cat export-status | grep status | awk '{print $2}' | sed 's/"//g' | sed 's/,//g')
while [ "$EXPORT_STATUS" = "processing" ]; do
sleep 15
curl "https://lon.images.api.rackspacecloud.com/v2/1000000/tasks/$TASKID_EXPORT" -X GET -H "X-Auth-Token: $TOKEN" -H "Content-Type: application/json" | python -mjson.tool > export-status
EXPORT_STATUS=$(cat export-status | grep status | awk '{print $2}' | sed 's/"//g' | sed 's/,//g')
done
# SET CORRECT CLOUD FILES NAME
CLOUD_FILES_NAME=$(cat export-cloudfiles | python -mjson.tool | grep image_uuid | awk '{print $2}' | sed 's/,//g' | sed 's/"//g')
## Download VHD Cloud from Cloud Files to this server
API_ENDPOINT='https://storage101.lon3.clouddrive.com/v1/MossoCloudFS_1000000'
# GET FILE FROM SOURCE CLOUD FILES
URL="$API_ENDPOINT/export/$CLOUD_FILES_NAME.vhd"
URL=${URL%$'\r'}
curl -s \
-H "X-Auth-Token: $TOKEN" \
-H "X-Project-Id: $TENANT" \
-H "Accept: application/json" \
-X GET "$API_ENDPOINT/export/$CLOUD_FILES_NAME.vhd" > $CLOUD_FILES_NAME.vhd
## NEW API USER/PASS REQUIRED FOR 2ND REGION
### DO NOT CHANGE ANYTHING ABOVE THIS POINT
USERNAME='yourmycloudusernamegoeshere'
APIKEY='yourapikeyfromsecondregiongoeshere'
### DO NOT CHANGE ANYTHING BELOW THIS POINT
## Now for uploading the VHD to Cloud Files to Destination REGION
API_ENDPOINT='https://storage101.ord1.clouddrive.com/v1/MossoCloudFS_900000'
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
curl -v -s \
-H "X-Auth-Token: $TOKEN" \
-H "X-Project-Id: 900000" \
-H "Accept: application/json" \
-X PUT "$API_ENDPOINT/import"
## Upload VHD Image to Cloud Files destination for import
curl -v -s \
-H "X-Auth-Token: $TOKEN" \
-H "X-Project-Id: 900000" \
-H "Accept: application/json" \
-X PUT "$API_ENDPOINT/import/$CLOUD_FILES_NAME.vhd" -T "$CLOUD_FILES_NAME.vhd"
# Find the Customer_ID
IMPORT_IMAGE_ENDPOINT=https://ord.images.api.rackspacecloud.com/v2/$CUSTOMER_ID
# This section simply retrieves the TOKEN
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
VHD_NOTES="autoimport-$SERVER_ID"
IMPORT_CONTAINER=import
VHD_FILENAME="$CLOUD_FILES_NAME.vhd"
curl -X POST "$IMPORT_IMAGE_ENDPOINT/tasks" \
-H "X-Auth-Token: $TOKEN" \
-H "Content-Type: application/json" \
-d "{\"type\":\"import\",\"input\":{\"image_properties\":{\"name\":\"$VHD_NOTES\"},\"import_from\":\"$IMPORT_CONTAINER/$VHD_FILENAME\"}}" |\
python -mjson.tool
As You can probably see my code is still rather rough, but it’s just so darn exciting that this script works from start to finish, nicely I just HAD to share it a bit earlier! The plan now is to add commandline function so that you can specify ./moveregion {SOURCE_REGION} {DEST_REGION} {SERVER_ID} {TENANT_ID} . Then a customer or a racker would only need these 4 variables to import and export images in an automated way.
I can rewrite the script in such a way that it would accept a .txt file of a couple of hundred cloud server UUID’s, and it would take the server UUID of each, use that uuid to create an image of each server, export to cloud files, import to cloud files, and then import to glance image store for the second region destination. Which naturally, would save hundreds of hours of human time doing this manually.. which is … nice 😀
I would really like to make a UI frontend, using something like Django, and utilize some form of ‘light’ database, that keeps track of all the API import/exports, and even provides estimated time for completion, but my UI skills are really limited to xhtml, css php and mysql.. I need a python or django guy to help out with some of this. If anyone is interested, please reach out to me.
This project will be avaialble on github soon