So, I had a friend who had recently bought his Raspberry Pi 3 and wanted to run retropie on it like I have been with my arcade cabinet.
The problem was the sandisk 64GB disk he had bought had some few less sectors on the disk, which meant my image was just a few bytes too big. What a bummer!
So I used this great tool by sirlagz to fix that.
#!/bin/bash
# Automatic Image file resizer
# Written by SirLagz
strImgFile=$1
if [[ ! $(whoami) =~ "root" ]]; then
echo ""
echo "**********************************"
echo "*** This should be run as root ***"
echo "**********************************"
echo ""
exit
fi
if [[ -z $1 ]]; then
echo "Usage: ./autosizer.sh "
exit
fi
if [[ ! -e $1 || ! $(file $1) =~ "x86" ]]; then
echo "Error : Not an image file, or file doesn't exist"
exit
fi
partinfo=`parted -m $1 unit B print`
partnumber=`echo "$partinfo" | grep ext4 | awk -F: ' { print $1 } '`
partstart=`echo "$partinfo" | grep ext4 | awk -F: ' { print substr($2,0,length($2)-1) } '`
loopback=`losetup -f --show -o $partstart $1`
e2fsck -f $loopback
minsize=`resize2fs -P $loopback | awk -F': ' ' { print $2 } '`
minsize=`echo $minsize+1000 | bc`
resize2fs -p $loopback $minsize
sleep 1
losetup -d $loopback
partnewsize=`echo "$minsize * 4096" | bc`
newpartend=`echo "$partstart + $partnewsize" | bc`
part1=`parted $1 rm 2`
part2=`parted $1 unit B mkpart primary $partstart $newpartend`
endresult=`parted -m $1 unit B print free | tail -1 | awk -F: ' { print substr($2,0,length($2)-1) } '`
truncate -s $endresult $1
It was a nice solution to my friends problem… the only problem now is the working image for my pi is not working with audio for him, and for some reason when he comes out of hte game and goes back to emulation station he loses the joystick input controller. That is kind of bizarre.
Does anyone know what could cause those secondary issues? I’m a bit stumped on this one.
Hey folks. So, recently I have been doing a bit of work on the Rackspace community, specifically trying to document and make as easy as possible the importing and exporting of cloud server VHD’s between Rackspace regions. This might be really useful if you are designing some HA or multi-region and/or load balancing solution that might be utilizing autoscale, and other kinds of redundancy too, but moving your ‘golden image’ between regions might be quite difficult if doing the entire process manually or step by step as I have documented in the below two articles:
Exporting Cloud server images from a Rackspace Region
https://community.rackspace.com/products/f/25/t/7089
Importing Cloud Server Images to a Rackspace Region
https://community.rackspace.com/products/f/25/t/7186
In this article I completely finish writing the ‘automation demo’ of how to specifically move images, without changing much at all, apart from one ‘serverID’ variable, and the source and destination. The script isn’t finished yet, however the last time I posted this on my blog I was so excited, I actually forgot to include the import function. (which is kind of important!) sorry about that.
echo "Exporting VHD to Cloud Files"
# This section simply retrieves the TOKEN
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
echo "IMAGEID detected as $IMAGEID"
# This section requests the Glance API to copy the cloud server image uuid to a cloud files container called export
# > export-cloudfiles
echo "THE IMAGE ID IS: $IMAGEID"
IMAGEID=${IMAGEID%$'\r'}
curl -v "https://lon.images.api.rackspacecloud.com/v2/$TENANT/tasks" -X POST -H "X-Auth-Token: $TOKEN" -H "Content-Type: application/json" -d '{"type": "export", "input": {"image_uuid": "'$IMAGEID'" , "receiving_swift_container": "export"}}' -o export-cloudfiles
echo "Export looks like"
echo "Waiting for Task to complete..."
## WAIT FOR TASKID EXPORT TO COMPLETE TO CLOUD FILES
# This section simply retrieves the TOKEN
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
# This section requests the Glance API to copy the cloud server image uuid to a cloud files container called export
curl "https://lon.images.api.rackspacecloud.com/v2/1000000/tasks/$TASKID_EXPORT" -X GET -H "X-Auth-Token: $TOKEN" -H "Content-Type: application/json" | python -mjson.tool > export-status
EXPORT_STATUS=$(cat export-status | grep status | awk '{print $2}' | sed 's/"//g' | sed 's/,//g')
while [ "$EXPORT_STATUS" = "processing" ]; do
sleep 15
curl "https://lon.images.api.rackspacecloud.com/v2/1000000/tasks/$TASKID_EXPORT" -X GET -H "X-Auth-Token: $TOKEN" -H "Content-Type: application/json" | python -mjson.tool > export-status
EXPORT_STATUS=$(cat export-status | grep status | awk '{print $2}' | sed 's/"//g' | sed 's/,//g')
done
# SET CORRECT CLOUD FILES NAME
CLOUD_FILES_NAME=$(cat export-cloudfiles | python -mjson.tool | grep image_uuid | awk '{print $2}' | sed 's/,//g' | sed 's/"//g')
## Download VHD Cloud from Cloud Files to this server
As You can probably see my code is still rather rough, but it’s just so darn exciting that this script works from start to finish, nicely I just HAD to share it a bit earlier! The plan now is to add commandline function so that you can specify ./moveregion {SOURCE_REGION} {DEST_REGION} {SERVER_ID} {TENANT_ID} . Then a customer or a racker would only need these 4 variables to import and export images in an automated way.
I can rewrite the script in such a way that it would accept a .txt file of a couple of hundred cloud server UUID’s, and it would take the server UUID of each, use that uuid to create an image of each server, export to cloud files, import to cloud files, and then import to glance image store for the second region destination. Which naturally, would save hundreds of hours of human time doing this manually.. which is … nice 😀
I would really like to make a UI frontend, using something like Django, and utilize some form of ‘light’ database, that keeps track of all the API import/exports, and even provides estimated time for completion, but my UI skills are really limited to xhtml, css php and mysql.. I need a python or django guy to help out with some of this. If anyone is interested, please reach out to me.
So I wrote a piece of software (basic) using BASh which exports Rackspace Cloud Servers between regions. It’s pure API CALLS using curl and I’m particularly proud of this piece, since it only took a day. (once I spent the whole of the next day figuring out an issue with the JSON and bash expansion for parameters to export the cloud server image to cloud files).
This is a super rough example of an automation-in-progress for cloud-servers between regions. Once you’ve set the script up, you simply change the serverid, and the script can do the rest, and you can migrate server by server, or perform batch migrates with this.
I’m going to refactor and rewrite it when I have time, but for now, here you are! Enjoy 😀
I hope that this is useful to people, particularly our customers.. when I release a finely tuned version that has commandline arguments support.
#!/bin/bash
echo "Exporting VHD to Cloud Files"
# This section simply retrieves the TOKEN
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
echo "IMAGEID detected as $IMAGEID"
# This section requests the Glance API to copy the cloud server image uuid to a cloud files container called export
# > export-cloudfiles
echo "THE IMAGE ID IS: $IMAGEID"
IMAGEID=${IMAGEID%$'\r'}
curl -v "https://lon.images.api.rackspacecloud.com/v2/$TENANT/tasks" -X POST -H "X-Auth-Token: $TOKEN" -H "Content-Type: application/json" -d '{"type": "export", "input": {"image_uuid": "'$IMAGEID'" , "receiving_swift_container": "export"}}' -o export-cloudfiles
echo "Export looks like"
echo "Waiting for Task to complete..."
## WAIT FOR TASKID EXPORT TO COMPLETE TO CLOUD FILES
# This section simply retrieves the TOKEN
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
# This section requests the Glance API to copy the cloud server image uuid to a cloud files container called export
curl "https://lon.images.api.rackspacecloud.com/v2/10101010/tasks/$TASKID_EXPORT" -X GET -H "X-Auth-Token: $TOKEN" -H "Content-Type: application/json" | python -mjson.tool > export-status
EXPORT_STATUS=$(cat export-status | grep status | awk '{print $2}' | sed 's/"//g' | sed 's/,//g')
while [ "$EXPORT_STATUS" = "processing" ]; do
sleep 15
curl "https://lon.images.api.rackspacecloud.com/v2/100101010/tasks/$TASKID_EXPORT" -X GET -H "X-Auth-Token: $TOKEN" -H "Content-Type: application/json" | python -mjson.tool > export-status
EXPORT_STATUS=$(cat export-status | grep status | awk '{print $2}' | sed 's/"//g' | sed 's/,//g')
done
# SET CORRECT CLOUD FILES NAME
CLOUD_FILES_NAME=$(cat export-cloudfiles | python -mjson.tool | grep image_uuid | awk '{print $2}' | sed 's/,//g' | sed 's/"//g')
## Download VHD Cloud from Cloud Files to this server
So, you may have noticed over the past weeks and months I have been a little bit quieter about the articles I have been writing. Mainly because I’ve been working on a new github project, which, although simple, and lightweight is actually really rather outrageously powerful.
https://github.com/aziouk/obsceneredundancy
Imagine being able to take 15+ redundant replica copies of your files, across 5 or 6 different datacentres. Rackspace Cloud Files API powered, but also with a lot of the flexibility of Bourne Again Shell (BASH).
This was actually quite a neat achievement and I am pleased with the results. There are still some limitations of this redundant replica application, and there are a few bugs, but it is a great proof of concept which shows what you can do with the API both quickly and cheaply (ish). Using filesystems as a service will be the future with some further innovation on the world wide network infrastructure, and it would only take a small breakthrough to rapidly alter the way that OS and machines boot/backup.
If you want to see the project and read the source code before I lay out and describe/explain the entire process of writing this software as well as how to deploy it with cron on linux, then you need wait no longer. Revision 1 alpha is now tested, ready and working in 5 different datacentres.
You can actually toggle which datacentres you wish to utilize as well, it is slightly flexible. The only important consideration here is to understand that there are some limitations such as a lack of de-duping, and this uses tar’s and swiftly, instead of directly querying the API. Since directly uploading thru the API a tar file is relatively simple, I will probably implement it like that as I have before and get rid of swiftly in future iterations, however such a project is really ideal for learning more about BASH , CRON, API and programmatic automation of and sequential filesystems utilizing functional programming and division of labour between workers,
https://github.com/aziouk/obsceneredundancy
Test it (please note it will be a little bit buggy on different environments and there is no instructions yet)
So, you want to configure NFS? This isn’t too difficult to do. First of all you will need to, in the simplest setup, create 2 servers, one acting as the NFS server which hosts the content and attached disks. The second server, acting as the client, which mounts the filesystem of the NFS server over the network to a local mount point on the client. In RHEL 7 this is remarkably easy to do.
Install and Configure NFS on the Server
Install dependencies
yum -y install nfs-utils rpcbind
Create a directory on the server
This is the directory we will share
mkdir -p /opt/nfs
Configure access for the client server on ip 10.0.0.2
vi /etc/exports
# alternatively you can directly pipe the configuration but I don't recommend it
echo "/opt/nfs 10.0.0.2(no_root_squash,rw,sync)" > /etc/exports
service rpcbind start; service nfs start
service nfs status
Install and configure NFS on the Client
Install dependencies & start rpcbind
yum install nfs-utils rpcbind
service rpcbind start
Create directory to mount NFS
# Directory we will mount our Network filesystem on the client
mkdir -p /mnt/nfs
# The server ip address is 10.0.0.1, with the path /opt/nfs, we want to mount it to the client on /mnt/nfs this could be anything like
# /mnt/randomdata-1234 etc as long as the folder exists;
mount 10.0.0.1:/opt/nfs /mnt/nfs/
Check that the NFS works
echo "meh testing.." > /mnt/nfs/testing.txt
cat /mnt/nfs/testing.txt
ls -al /mnt/nfs
You should see the filesystem now has testing.txt on it. Confirming you setup NFS correctly.
Make NFS mount permanent by enabling the service permanently, and adding the mount to fstab
This will cause the server to automount the fs during boot time
systemctl enable nfs-server
vi /etc/fstab
10.0.0.1:/opt/nfs /mnt/nfs nfs defaults 0 0
# OR you could simply pipe the configuration to the file (this is really dangerous though)
# Unless you are absolutely sure what you are doing
echo "10.0.0.1:/opt/nfs /mnt/nfs nfs defaults 0 0" >> /etc/fstab
If you reboot the client now, you should see that the NFS mount comes back.
So, in a dream last night, I woke up realising I had forgot to write my automated load balancer connectivity checker.
Basically, sometimes a customer will complain their site is down because their ‘load balancer is broken’! In many cases, this is actually due to a firewall on one of the nodes behind the load balancer, or an issue with the webserver application listening on the port. So, I wrote a little piece of automation in the form of a BASH script, that accepts an Load Balancer ID and then uses the API to pull the server nodes behind that Load Balancer, including the ports being used to communicate, and then uses, either netcat or nmap to check that port for connectivity. There were a few ways to achieve this, but the below is what I was happiest with.
#!/bin/bash
# Username used to login to control panel
USERNAME='mycloudusernamegoeshere'
# Find the APIKey in the 'account settings' part of the menu of the control panel
APIKEY="apikeygoeshere"
# Your Rackspace account number (the number that is in the URL of the control panel after logging in)
ACCOUNT=100101010
# Your Rackspace loadbalancerID
LOADBALANCERID=157089
# Rackspace LoadBalancer Endpoint
ENDPOINT="https://lon.loadbalancers.api.rackspacecloud.com/v1.0"
# This section simply retrieves and sets the TOKEN
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
# (UNUSED) METHOD 1Extract IP addresses (Currently assuming port 80 only)
#curl -H "X-Auth-Token: $TOKEN" -H "Accept: application/json" -X GET "$ENDPOINT/$ACCOUNT/loadbalancers/$LOADBALANCERID/nodes" | jq .nodes[].address | xargs -i nmap -p 80 {}
# (UNUSED) Extract ports
# curl -H "X-Auth-Token: $TOKEN" -H "Accept: application/json" -X GET "$ENDPOINT/$ACCOUNT/loadbalancers/$LOADBALANCERID/nodes" | jq .nodes[].port | xargs -i nmap -p 80 {}
# I opted for using this method to extract the important detail
curl -H "X-Auth-Token: $TOKEN" -H "Accept: application/json" -X GET "$ENDPOINT/$ACCOUNT/loadbalancers/$LOADBALANCERID/nodes" | jq .nodes[].address | sed 's/"//g' > address.txt
curl -H "X-Auth-Token: $TOKEN" -H "Accept: application/json" -X GET "$ENDPOINT/$ACCOUNT/loadbalancers/$LOADBALANCERID/nodes" | jq .nodes[].port > port.txt
# Loop thru both output files sequentially, order is important
# WARNING script does not ignore whitespace
while read addressfile1 <&3 && read portfile2 <&4; do
ncat $addressfile1 $portfile2
done 3
Output looks a bit like;
# ./lbtest.sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5143 100 5028 100 115 4731 108 0:00:01 0:00:01 --:--:-- 4734
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 225 100 225 0 0 488 0 --:--:-- --:--:-- --:--:-- 488
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 225 100 225 0 0 679 0 --:--:-- --:--:-- --:--:-- 681
Ncat: No route to host.
Ncat: Connection timed out.
I plan to add some additional support that will check the load balancer is up, AND the servicenet connection between the cloud servers.
Please note that this script must be run on a machine with access to servicenet network, in the same Rackspace Datacenter to be able to check servicenet connectivity of servers. The script can give false positives if strict firewall rules are setup on the cloud server nodes behind the load balancer. It's kind of alpha-draft but I thought I would share it as a proof of concept.
You will need to download and install jq to use it. To download jq please see; https://stedolan.github.io/jq/download/
Today we had a customer that needed to perform a first generation server to next generation migration however they cannot have SELinux enabled during this process.
I explain to the customer how to disable this, it’s pretty simple.
vi /etc/sysconfig/selinux
SELINUX=enforcing
Needs to be changed to
SELINUX=disabled
Job done. A simple one but nonetheless important stuff. If you wanted to automate this it would look something like this;
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g'/etc/selinux/config
This sed oneliner simply swaps SELINUX=enforcing to SELINUX=disabled, pretty simple stuffs. It will work on CentOS6 and 7 anyway, and should but I can’t guarantee work on CentOS 5.
So, we are configuring some openstack and kvm stuff at work for some projects. We’re ‘cloudy’ guys. What can I say? 😀 One Issue I had when installing xenserver, underneath KVM.
(why would we do this?) In our testing environment we’re using a single OnMetal v2 server, and, instead of running xenserver directly on the server, and requiring additional servers, we are using a single 128GB RAM hypervisor for the test environment. One issue though is that Windows is only supported with xenserver when directly run on the ‘host’. Because Xen is running virtualized under KVM we have a problem.
Enter, tested virtualization support. Hardware virtualization assist support will now work for xenserver thru KVM, which means I can boot windows servers. YAY! uh.. 😉 kinda.
Check if Nested hardware virtualization assist is enabled
So, you have lost your Windows Administrator password for your Rackspace cloud server? I’d like to thank my friend Cory for providing the link details for how to do this.
No problem. Simply put the Windows VM into rescue mode using a Linux image (yup!)
Put Windows VM into Rescue mode using Linux image
# Initiate rescue using the CentOS 7 image for the server uuid 0b67faf7-bc56-4844-ad0b-16e39f289ef6
$ nova me rescue --password mypasswordforrescuemodehere --image 7fade26a-0cca-415f-a988-49c021768fca 0b67faf7-bc56-4844-ad0b-16e39f289ef6
If you’ve broken your Rackspace server and you don’t know how to perform the above step, send a ticket to Rackspace support and they should be able to put your server in rescue so you can reset the password of your windows machine!
SSH to rescue server
ssh root@myserveriphere
Check which disk is Windows NTFS
# fdisk -l
Disk /dev/xvdc: 2147 MB, 2147483648 bytes, 4194304 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x0003e9b3
Device Boot Start End Blocks Id System
/dev/xvdc1 2048 4194303 2096128 83 Linux
Disk /dev/xvdb: 85.9 GB, 85899345920 bytes, 167772160 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xfcb073fc
Device Boot Start End Blocks Id System
/dev/xvdb1 * 2048 167770111 83884032 7 HPFS/NTFS/exFAT
Disk /dev/xvda: 85.9 GB, 85899345920 bytes, 167772160 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x00070dc0
Here we can see that the disk we want is /dev/xvdb1 since this is the HPFS/NTFS/exFAT partition format used by windows. The rescue mode builds a new server and disk, attaching your old disk as the ‘b’ disk, xvdb. Lets mount the disk and install the application we need to wipe the password for the box.
Mount the disk
yum update -y
yum install ntfs-3g -y
mount /dev/xvdb1 /mnt
root@RESCUE-test config]# chntpw -u "Administrator" SAM
chntpw version 0.99.6 110511 , (c) Petter N Hagen
Hive name (from header): <\SystemRoot\System32\Config\SAM>
ROOT KEY at offset: 0x001020 * Subkey indexing type is: 666c
File size 262144 [40000] bytes, containing 6 pages (+ 1 headerpage)
Used for data: 255/20712 blocks/bytes, unused: 13/3672 blocks/bytes.
* SAM policy limits:
Failed logins before lockout is: 0
Minimum password length : 0
Password history count : 0
| RID -|---------- Username ------------| Admin? |- Lock? --|
| 01f4 | Administrator | ADMIN | |
| 01f5 | Guest | | dis/lock |
---------------------> SYSKEY CHECK <-----------------------
SYSTEM SecureBoot : -1 -> Not Set (not installed, good!)
SAM Account\F : 0 -> off
SECURITY PolSecretEncryptionKey: -1 -> Not Set (OK if this is NT4)
Syskey not installed!
RID : 0500 [01f4]
Username: Administrator
fullname:
comment : Built-in account for administering the computer/domain
homedir :
User is member of 1 groups:
00000220 = Administrators (which has 1 members)
Account bits: 0x0010 =
[ ] Disabled | [ ] Homedir req. | [ ] Passwd not req. |
[ ] Temp. duplicate | [X] Normal account | [ ] NMS account |
[ ] Domain trust ac | [ ] Wks trust act. | [ ] Srv trust act |
[ ] Pwd don't expir | [ ] Auto lockout | [ ] (unknown 0x08) |
[ ] (unknown 0x10) | [ ] (unknown 0x20) | [ ] (unknown 0x40) |
Failed login count: 0, while max tries is: 0
Total login count: 15
- - - - User Edit Menu:
1 - Clear (blank) user password
2 - Edit (set new) user password (careful with this on XP or Vista)
3 - Promote user (make user an administrator)
(4 - Unlock and enable user account) [seems unlocked already]
q - Quit editing user, back to user select
Select: [q] > 1
Password cleared!
Hives that have changed:
# Name
0
Write hive files? (y/n) [n] : y
0 - OK
It’s been done, yay!
Unrescue the cloud server, either from control panel or using nova
abull-mb:~ adam$ supernova me unrescue 0b67faf7-bc56-4844-ad0b-16e39f289ef6
Yay! We now automatically bypass the ordinary login screen so we can get into the server to reconfigure it properly again.
You might have some questions about… setting up nova.
Setting up Nova
# Nova configuration
#export OS_AUTH_URL=https://lon.identity.api.rackspacecloud.com/v2.0/
#export OS_AUTH_SYSTEM=rackspace_uk
#export OS_REGION_NAME=LON
#export OS_USERNAME=mycloudusernamehere
# Tenant Name is customer number shown in url of mycloud control panel
##export OS_TENANT_NAME=10101010
#export NOVA_RAX_AUTH=1
#export OS_PASSWORD=mycloudapikeyhere
# Project ID is customer number shown in url of mycloud control panel
#export OS_PROJECT_ID=100101010
#export OS_NO_CACHE=1
These ‘environment variables’ should be put in a file like your .bash_profile. Then you will want to source it before using nova
source .bash_profile
or
. .bash_profile
This just sets the variables on the commandline so they can be used by nova. It is possible to provide all of the credentials on the nova commandline as described in previous articles on this blog concerning nova.
Using nova without .bash_profile or environment variables
for more details about how to install python based nova, used in this article, please see;
https://support.rackspace.com/how-to/installing-python-novaclient-on-linux-and-mac-os/
So, you want to run your own hypervisor using xenserver, but you want to have some of the flexibility of KVM too. This instructional guide explains how to install and configure KVM with virt-manager and with X11 forwarding. We will go step by step. In this case I am using a mac.
Step 1 – Create Rackspace onmetalv2 server
In this case I’ll be using a 40 cpu 128GB machine as the host utilizing the new onmetalv2 server range offered by Rackspace public cloud.
Please note that this is a bare metal server, not a cloud server, however it is offered by the same cloud platform at mycloud.rackspace.co.uk
This simply allows X11 forwarding for Mac users which needs to be done at the client side. Then you can virtualize any application you like on the client, but running the application such as firefox , or even a virtual machine on the remote server. SSHv2 is beautiful. That’s it you’ve completed the most important steps.
Running virt-manager for the first time
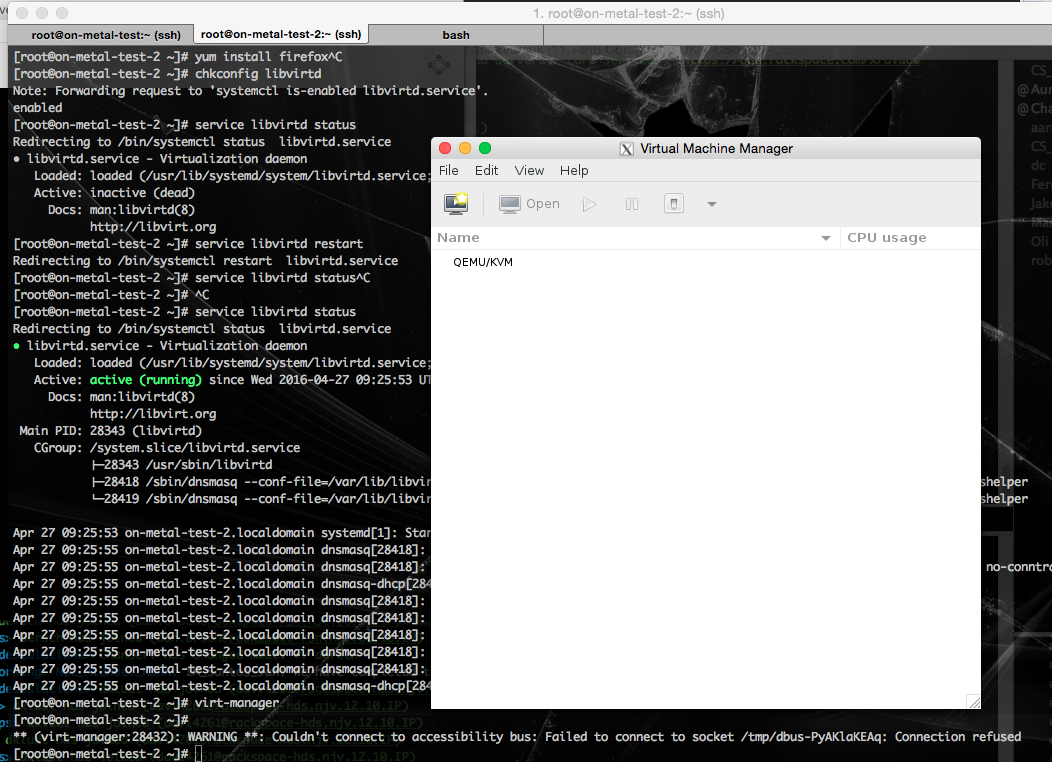
[root@on-metal-test-2 ~]# virt-manager
After running the above command you will see something like the image below. You’ll see an X window open on your local client machine, which is associated with an application running on the remote server your connected to via SSH. This is pretty damn cool.
Lets take this further and install firefox to demonstrate how awesome this is!
yum install firefox -y
Now we’re using firefox thru ssh, much better and more convenient to use X11 forwarding for this, than using a proxy for instance on the client configured with tunnel or vpn.
Nice!
Lets take it a bit further and start installing xen server with KVM. I am very tempted to use ZFS for this since onmetal v2 has 2 1600GB disks…
Create partitions for KVM store
fdisk -l
fdisk /dev/sdc
# type m , then type n, then type p, enter, enter, enter, enter, then type w
fdisk /dev/sdd
# type m , then type n, then type p, enter, enter, enter, enter, then type w
Create filesystem for KVM store
[root@on-metal-test-2 ~]# mkfs.ext3 /dev/sdc1 && mkfs.ext3 /dev/sdd1
mke2fs 1.42.9 (28-Dec-2013)
Discarding device blocks: done
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
97656832 inodes, 390624640 blocks
19531232 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
11921 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968,
102400000, 214990848
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
mke2fs 1.42.9 (28-Dec-2013)
Discarding device blocks: done
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
97656832 inodes, 390624640 blocks
19531232 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
11921 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968,
102400000, 214990848
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
Now we have created the filesystem. What about creating the ZFS partition. To do this we need to go thru a fairly laborious process (at least if you don’t know what your doing). As I discovered my yum installation wasn’t automatically providing the correct devel source for the kernel to use the ZFS DKMS module. As ZFS is really a native BSD package.
One of the problems I had was this
Loading new spl-0.6.5.6 DKMS files...
Building for 3.10.0-327.10.1.el7.x86_64
Module build for kernel 3.10.0-327.10.1.el7.x86_64 was skipped since the
kernel source for this kernel does not seem to be installed.
Installing : zfs-dkms-0.6.5.6-1.el7.centos.noarch 4/6
Loading new zfs-0.6.5.6 DKMS files...
Building for 3.10.0-327.10.1.el7.x86_64
Module build for kernel 3.10.0-327.10.1.el7.x86_64 was skipped since the
kernel source for this kernel does not seem to be installed.
This can be checked out in more detail by running an;
This gave me the right version of the devel kernel I needed to install ZFS to my current kernel with a module, as opposed to completely recompiling the whole thing. Nice!
Now we’ve created our partition and filesystem and configured ZFS we can run the virtual machines off the new kvm partition store. simples
Click top left icon on corner to create new VM
Download the Xenserver ISO to /root of hypervisor
root@on-metal-test-2 ~]# wget http://downloadns.citrix.com.edgesuite.net/10175/XenServer-6.5.0-xenserver.org-install-cd.iso
--2016-04-27 10:29:22-- http://downloadns.citrix.com.edgesuite.net/10175/XenServer-6.5.0-xenserver.org-install-cd.iso
Resolving downloadns.citrix.com.edgesuite.net (downloadns.citrix.com.edgesuite.net)... 104.86.110.32, 104.86.110.49
Connecting to downloadns.citrix.com.edgesuite.net (downloadns.citrix.com.edgesuite.net)|104.86.110.32|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 603744256 (576M) [application/octet-stream]
Saving to: ‘XenServer-6.5.0-xenserver.org-install-cd.iso’
100%[====================================================================================================================================>] 603,744,256 17.6MB/s in 38s
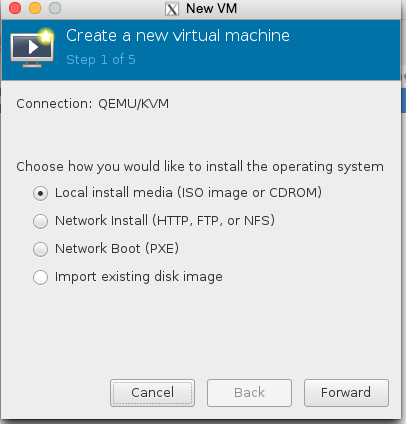
Select Local Media (we’re going to use a Xenserver ISO)
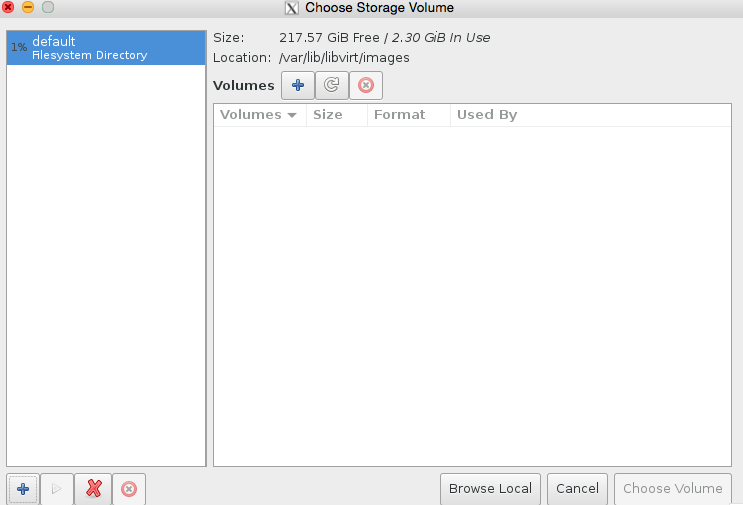
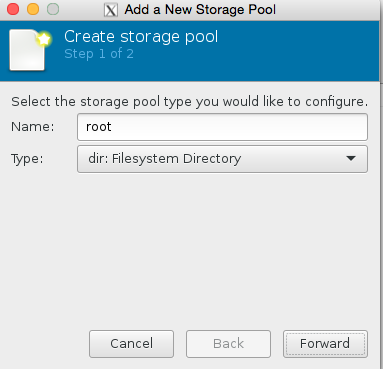
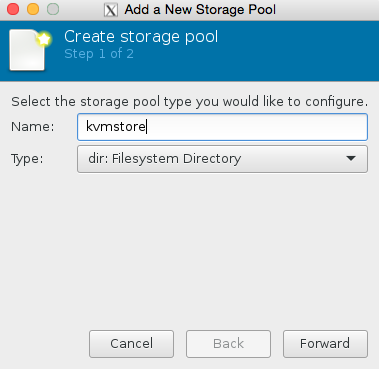
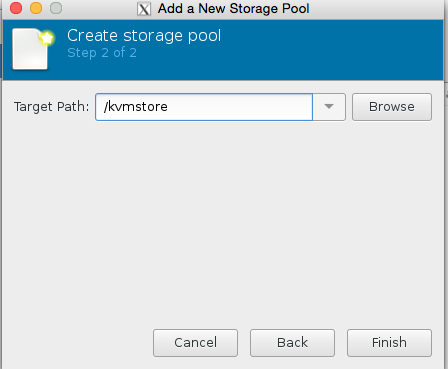
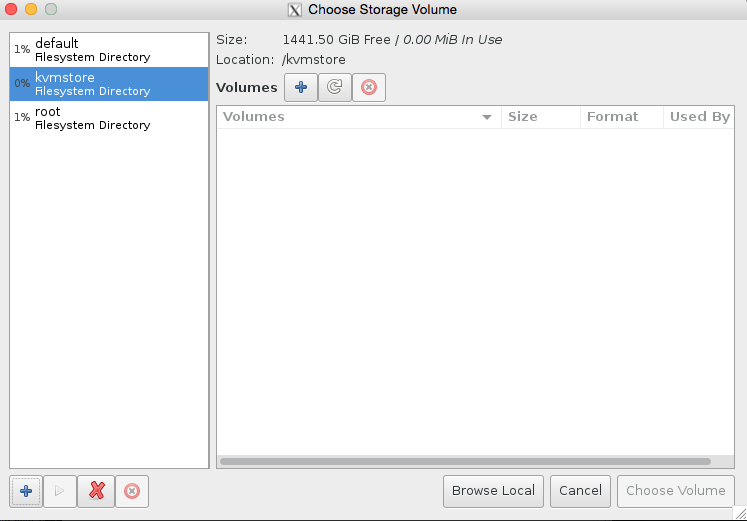
Click browse, then press the bottom left + icon to add some pools. We’re going to add /root which has our iso in it, and we’re also going to add kvmstore aswell.
Congratulations you have now added the stores. Now all we need to do is finish configuring the VM.
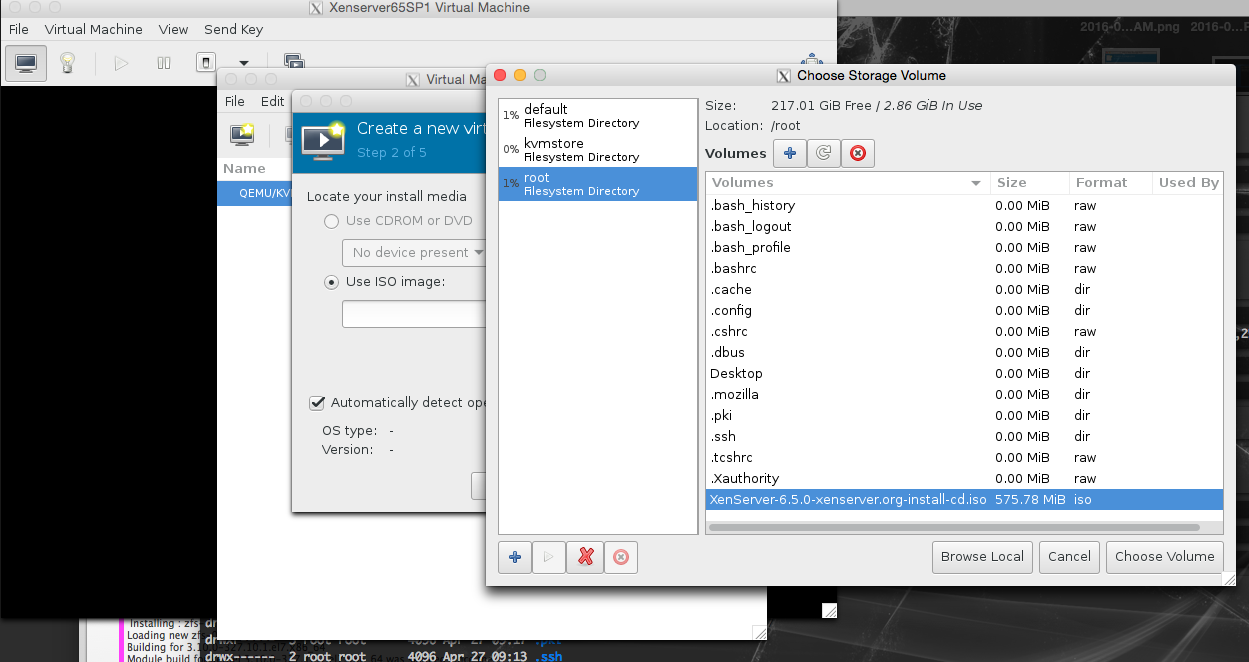
We want to select the root partition now we have set up the pool, and choose the xenserver iso we just recently downloaded.
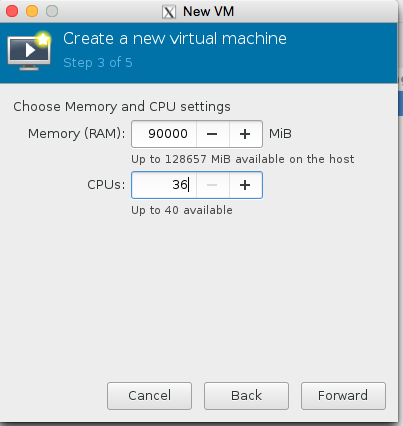
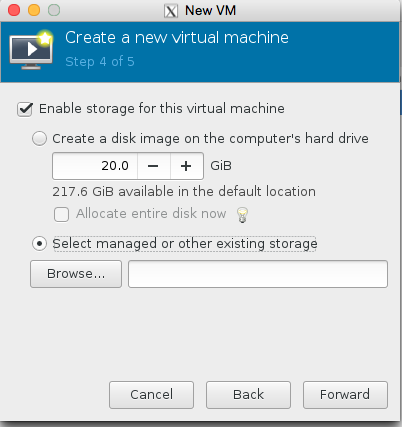
We are almost there now! Lets set the number of cpu and ram! Also lets make sure we use the kvmstore we just setup instead of the ‘main disk’ of the server.
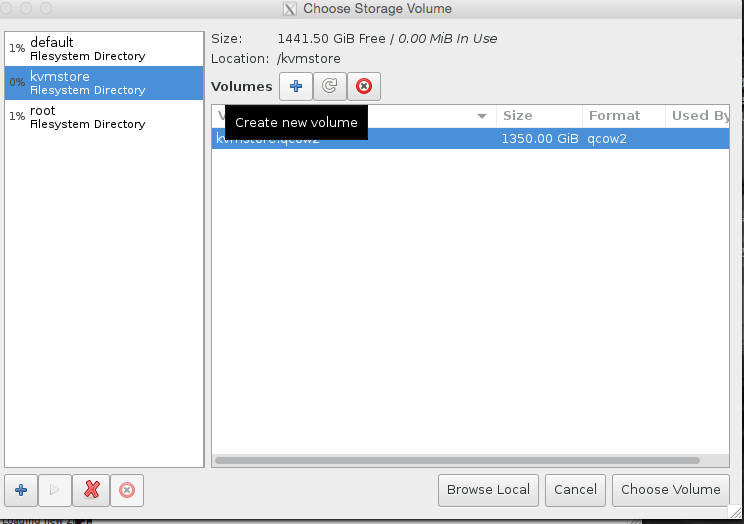
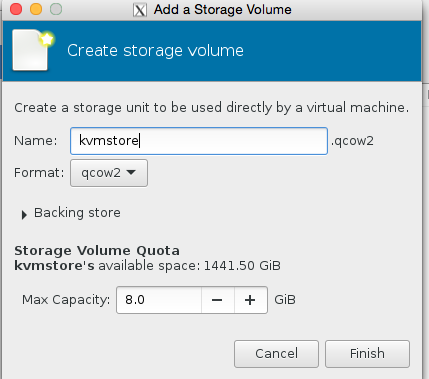
Select our KVM store ‘pool’ on the left hand side, and then press + to add the kvmstore.qcow2 volume, see the images for illustration.
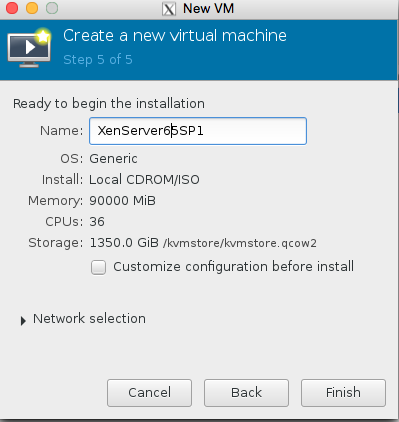
click choose volume at the bottom left to confirm! And finally name the server
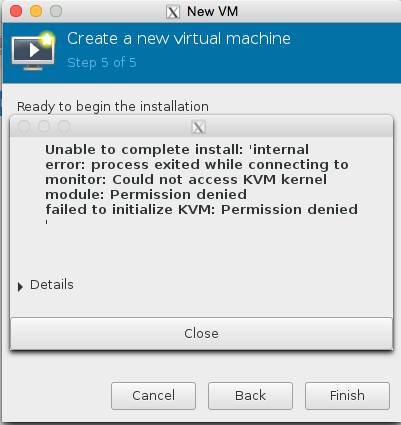
awwww crap , we got this error because the libvirtd kvm configuration isnt running as root
This can be quickly resolved by editing the /etc/libvirt/qemu.conf and making sure user = “root” and group = “root” are present.