So, I was thinking about the problem with cloning CBS volumes, where if you want to make several 64 copies of a CBS disk or more in a quick time. But what happens is they are built sequentially and queued. They are copied one at a time. So when a windows customer approached us, a colleague reached out to me to see if there was any other way of doing this thru snapshots or clones. In fact there was, and cinder is to be considered a fox, fast and cunning and unseen , but it is trapped inside a cage called glance.
This is about overcoming those limitations, introducing TOR-CBS
Parallel CBS Building with Openstack Cinder
This is all about making the best of the infrastructure that is there. Cinder is massively distributed so, building 64 parallel copies is achievable at a much higher parallel bandwidth, and for those reasons it is a ‘tor like’ system. A friend of mine compared it to cellular division. There is a kind of organic nature to the method applied, as all children are used as new parents for copy. This explains the efficiency and speed of the system. I.e. the more servers you want to build the more time you save .
When this actually worked for the first time I had to take a step back. It really meant that building 64 CBS would take an hour, and building 128 of them would take 1 hour and 10 minutes. Damn, that’s fast!
When you’ve got all thatI.e. clone 1 disk to create a second disk. Clone both the first and the second disk to make four disks. Clone the four to make 8 in total. Clone 8 to make 16 in total. 32, 64, 128, 256, 512, 1024, 2048. Your cluster can double in size in roughly 10 minutes a go provided that Cinder service has the infrastructure in place. This appears to be a new potentially revolutionary way of building out in the cloud.
See the diagram below for a proper illustration and explanation.
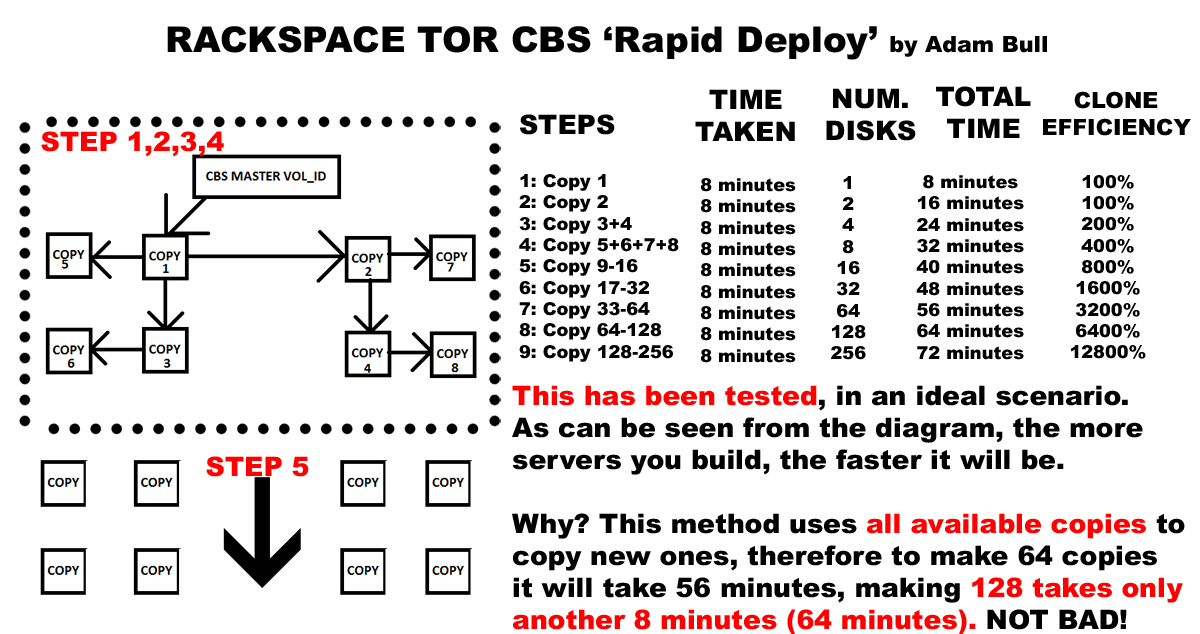
As you can see the one for one copy in the 9th or 10th step is in the tens of thousands of percent more efficient!! The reason is because CBS clone is a one to one copy, and even if you specify to build 50 from a single volume id source, it will incrementally build them, one by one.
My system works the same, except it uses all of the available disks already built from the previous n steps, therefore giving an n’th exponent of amplification of efficiency per step, in other words, ‘something for nothing’. It also properly utilizes the distributed nature of CBS and very many network ports. Instead of utilizing a single port from the source volume, which is ultimately the restricting bottleneck factor in spinning up large cloud solutions.
I am absolutely delighted. IT WORKS!!
The Code
build-cbs.sh
USERNAME='MYCLOUDUSERNAMEHERE'
APIKEY='MYAPIKEYHERE'
ACCOUNT_NUMBER=10010111
API_ENDPOINT="https://lon.blockstorage.api.rackspacecloud.com/v1/$ACCOUNT_NUMBER/volumes"
MASTER_CBS_VOL_ID="MY-MASTER-VOLUME-ID-HERE"
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
echo "Using MASTER_CBS_VOL_ID $MASTER_CBS_VOL_ID.."
sleep 2
# Populate CBS
# No longer using $1 and $2 as unnecessary now we have cbs-fork-step
for i in `seq 1 2`;
do
echo "Generating CBS Clone #$i"
curl -s -vvvv \
-X POST "$API_ENDPOINT" \
-H "X-Auth-Token: $TOKEN" \
-H "X-Project-Id: $ACCOUNT_NUMBER" \
-H "Accept: application/json" \
-H "Content-Type: application/json" -d '{"volume": {"source_volid": "'$MASTER_CBS_VOL_ID'", "size": 50, "display_name": "win-'$i'", "volume_type": "SSD"}}' | jq .volume.id | tr -d '"' >> cbs.created.newstep
done
echo "Giving CBS 15 minute grace time for 50 CBS clone"
z=0
spin() {
local -a marks=( '/' '-' '\' '|' )
while [[ $z -lt 500 ]]; do
printf '%s\r' "${marks[i++ % ${#marks[@]}]}"
sleep 1
let 'z++'
done
}
spin
echo "Listing all CBS Volume ID's created"
cat cbs.created.newstep
# Ensure all of the initial created cbs end up in the master file
cat cbs.created.newstep >> cbs.created.all
echo "Initial Copy completed"
So the first bit is simple, the above uses the openstack Cinder API endpoint to create two copies of the master. It takes a bit longer the initial process, but if your building 64 to infinite servers this is going to be the most efficient and fastest way to do it. The thing is, we want to recursively build CBS in steps.
Enter cbs-fork-step.sh
cbs-fork-step.sh
USERNAME='MYCLOUDUSERNAMEHERE'
APIKEY='MYAPIKEYHERE'
ACCOUNT_NUMBER=10010111
API_ENDPOINT="https://lon.blockstorage.api.rackspacecloud.com/v1/$ACCOUNT_NUMBER/volumes"
TOKEN=`curl https://identity.api.rackspacecloud.com/v2.0/tokens -X POST -d '{ "auth":{"RAX-KSKEY:apiKeyCredentials": { "username":"'$USERNAME'", "apiKey": "'$APIKEY'" }} }' -H "Content-type: application/json" | python -mjson.tool | grep -A5 token | grep id | cut -d '"' -f4`
z=0
spin() {
local -a marks=( '/' '-' '\' '|' )
while [[ $z -lt 400 ]]; do
printf '%s\r' "${marks[i++ % ${#marks[@]}]}"
sleep 1
let 'z++'
done
}
count=$1
#count=65;
while read n; do
echo ""
# Populate CBS TOR STEPPING
echo "Generating TOR CBS Clone $count::$n"
date
curl -s \
-X POST "$API_ENDPOINT" \
-H "X-Auth-Token: $TOKEN" \
-H "X-Project-Id: $ACCOUNT_NUMBER" \
-H "Accept: application/json" \
-H "Content-Type: application/json" -d '{"volume": {"source_volid": "'$n'", "size": 50, "display_name": "win-'$count'", "volume_type": "SSD"}}' | jq .volume.id | tr -d '"' >> cbs.created.newstep
((count=count+1))
done < cbs.created.all
cat cbs.created.newstep > cbs.created.all
echo "Waiting 8 minutes for Clone cycle to complete.."
spin
As you can see from the above, the volume master ID disappears, we’re now using the 2 CBS VOL ID’s that were initially copied in the first build-cbs.sh file. From now on, we’ll iterate while reading n lines of the cbs.crated.newstep file. For redundancy cbs.created.all is used as well. The problem is this is a fixed iterative loop, what about controlling how many times this runs?
Also, we obviously need to keep count and track of each CBS, so we call them win-‘$count’, the ‘ ‘ is for termination/escape from the ‘” “‘. This allows each CBS to get the correct logical name based on the sequence, but in order for this to work properly, we need to put it all together in a master.sh file. The master forker, which adds an extra loop traversal to the design.
Putting it all together
master.sh
drwxr-xr-x. 2 root root 4096 Oct 7 10:44 curl
drwxr-xr-x. 2 root root 4096 Nov 12 13:48 customer
drwxr-xr-x. 4 root root 4096 Oct 12 15:07 .gem
# Master Controller file
# Number of Copy Steps Minimum 2 Maximum 9
# Steps 2=2 copies, 3=4 copies, 4=8, 5=16, 6=32, 7=64, 8=128, 9=256
# Steps 2=4 copies, 3=8 copies, 4=16, 5=32, 6=64, 7=128
# The steps variable determines how many identical Tor-copies of the CBS you wish to make
steps=6
rm cbs.created.all
rm cbs.created.newstep
touch cbs.created.all
touch cbs.created.newstep
figlet TOR CBS
echo ‘By Adam Bull, Rackspace UK’
sleep 2
echo “This software is alpha”
sleep 2
echo “Initiating initial Copy using $MASTER_CBS_VOLUME_ID”
# Builds first copy
./build-cbs.sh
count=4
for i in `seq 1 $steps`; do
let ‘count–‘
./cbs-fork-step.sh $count
let ‘count = (count * 2)’
done
echo “Attaching CBS and Building Nova Compute..”
./build-nova.sh
This code is still alpha, but it works really nicely. The output of the script looks like;
# ./master.sh
_____ ___ ____ ____ ____ ____
|_ _/ _ \| _ \ / ___| __ ) ___|
| || | | | |_) | | | | _ \___ \
| || |_| | _ < | |___| |_) |__) |
|_| \___/|_| \_\ \____|____/____/
By Adam Bull, Rackspace UK
This software is alpha
Initiating initial Copy using
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5143 100 5028 100 115 5013 114 0:00:01 0:00:01 --:--:-- 5017
Generating TOR CBS Clone 3::defd5aa1-2927-444c-992d-fba6602f117c
Wed Mar 2 12:25:26 UTC 2016
Generating TOR CBS Clone 4::8283420f-b02a-4094-a857-aedf73dffcc3
Wed Mar 2 12:25:27 UTC 2016
Waiting 8 minutes for Clone cycle to complete..
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5143 100 5028 100 115 4942 113 0:00:01 0:00:01 --:--:-- 4948
Generating TOR CBS Clone 5::defd5aa1-2927-444c-992d-fba6602f117c
Wed Mar 2 12:32:10 UTC 2016
Generating TOR CBS Clone 6::8283420f-b02a-4094-a857-aedf73dffcc3
Wed Mar 2 12:32:11 UTC 2016
Generating TOR CBS Clone 7::822687a8-f364-4dd1-8a8a-3d52687454dd
Wed Mar 2 12:32:12 UTC 2016
Generating TOR CBS Clone 8::4a97d22d-03c1-4b14-a64c-bbf3fa5bab07
Wed Mar 2 12:32:12 UTC 2016
Waiting 8 minutes for Clone cycle to complete..
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5143 100 5028 100 115 5186 118 --:--:-- --:--:-- --:--:-- 5183
Generating TOR CBS Clone 9::defd5aa1-2927-444c-992d-fba6602f117c
Wed Mar 2 12:38:56 UTC 2016
Generating TOR CBS Clone 10::8283420f-b02a-4094-a857-aedf73dffcc3
Wed Mar 2 12:38:56 UTC 2016
Generating TOR CBS Clone 11::822687a8-f364-4dd1-8a8a-3d52687454dd
Wed Mar 2 12:38:57 UTC 2016
Generating TOR CBS Clone 12::4a97d22d-03c1-4b14-a64c-bbf3fa5bab07
Wed Mar 2 12:38:58 UTC 2016
Generating TOR CBS Clone 13::42145009-33a7-4fc4-9865-da7a82e943c1
Wed Mar 2 12:38:58 UTC 2016
Generating TOR CBS Clone 14::58db8ae2-2e0e-4629-aad6-5c228eb4b342
Wed Mar 2 12:38:59 UTC 2016
Generating TOR CBS Clone 15::d0bf36cb-6dd5-4ed3-8444-0e1d61dba865
Wed Mar 2 12:39:00 UTC 2016
Generating TOR CBS Clone 16::459ba327-de60-4bc1-a6ad-200ab1a79475
Wed Mar 2 12:39:00 UTC 2016
Waiting 8 minutes for Clone cycle to complete..
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5143 100 5028 100 115 4953 113 0:00:01 0:00:01 --:--:-- 4958
Generating TOR CBS Clone 17::defd5aa1-2927-444c-992d-fba6602f117c
Wed Mar 2 12:45:44 UTC 2016
Generating TOR CBS Clone 18::8283420f-b02a-4094-a857-aedf73dffcc3
Wed Mar 2 12:45:45 UTC 2016
Generating TOR CBS Clone 19::822687a8-f364-4dd1-8a8a-3d52687454dd
Wed Mar 2 12:45:45 UTC 2016
Generating TOR CBS Clone 20::4a97d22d-03c1-4b14-a64c-bbf3fa5bab07
Wed Mar 2 12:45:46 UTC 2016
Generating TOR CBS Clone 21::42145009-33a7-4fc4-9865-da7a82e943c1
Wed Mar 2 12:45:46 UTC 2016
Generating TOR CBS Clone 22::58db8ae2-2e0e-4629-aad6-5c228eb4b342
Wed Mar 2 12:45:47 UTC 2016
Generating TOR CBS Clone 23::d0bf36cb-6dd5-4ed3-8444-0e1d61dba865
Wed Mar 2 12:45:48 UTC 2016
Generating TOR CBS Clone 24::459ba327-de60-4bc1-a6ad-200ab1a79475
Wed Mar 2 12:45:48 UTC 2016
Generating TOR CBS Clone 25::9b10b078-c82d-48cd-953e-e99d5e90774a
Wed Mar 2 12:45:49 UTC 2016
Generating TOR CBS Clone 26::0692c7dd-6db0-43e6-837d-8cc82ce23c78
Wed Mar 2 12:45:50 UTC 2016
Generating TOR CBS Clone 27::f2c4a89e-fc37-408a-b079-f405e150fa96
Wed Mar 2 12:45:50 UTC 2016
Generating TOR CBS Clone 28::5077f4d8-e5e1-42b6-af58-26a0b55ff640
Wed Mar 2 12:45:51 UTC 2016
Generating TOR CBS Clone 29::f18ec1c3-1698-4985-bfb9-28604bbdf70b
Wed Mar 2 12:45:52 UTC 2016
Generating TOR CBS Clone 30::fd96c293-46e5-49e4-85d5-5181d6984525
Wed Mar 2 12:45:52 UTC 2016
Generating TOR CBS Clone 31::9ea40b0d-fb60-4822-a538-3b9d967794a2
Wed Mar 2 12:45:53 UTC 2016
Generating TOR CBS Clone 32::ea7e2c10-d8ce-4f22-b8b5-241b81dff08c
Wed Mar 2 12:45:54 UTC 2016
Waiting 8 minutes for Clone cycle to complete..
/